
Click Here to be Taken to the Megathread!
from [email protected]
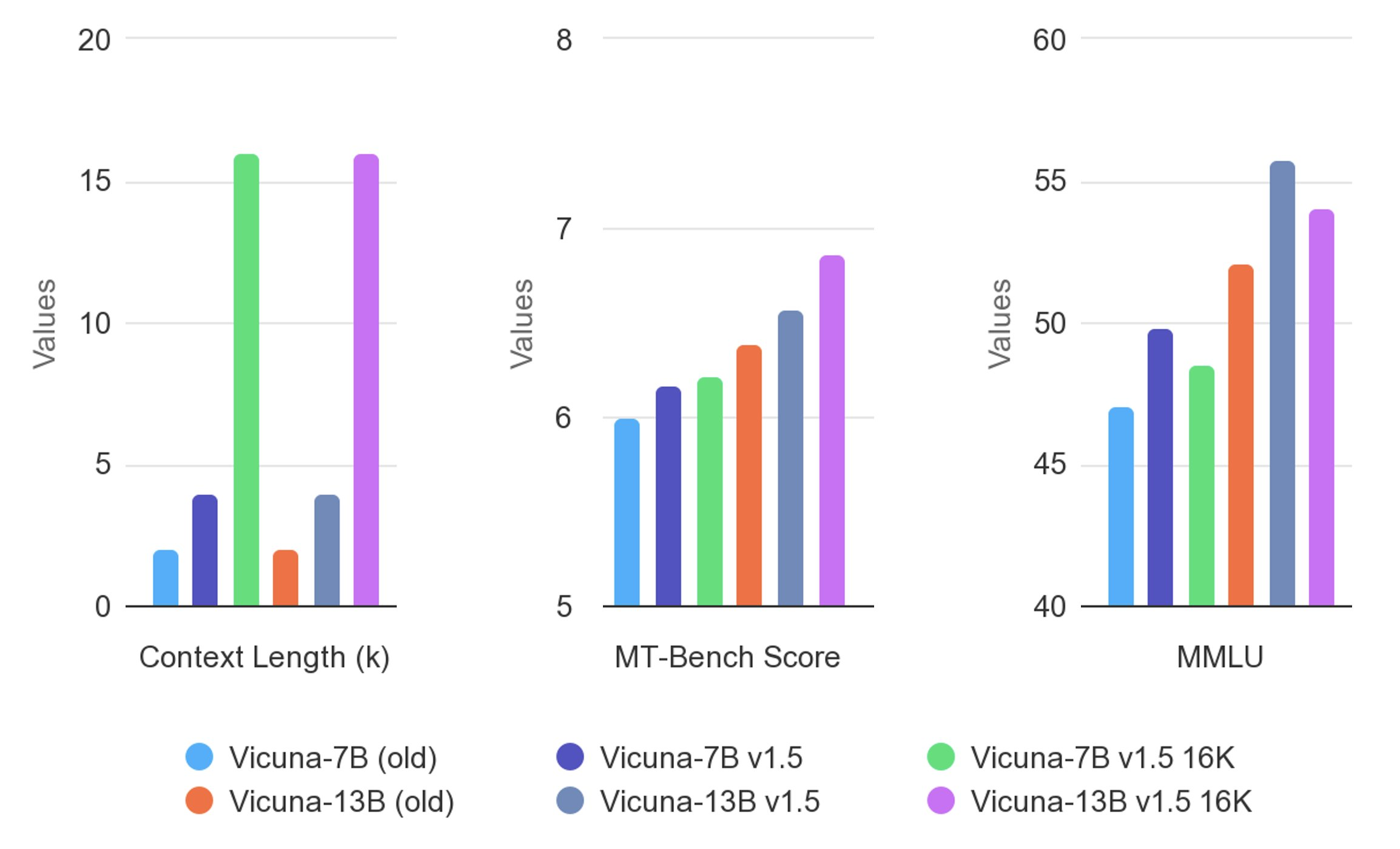
Vicuna v1.5 Has Been Released!
Shoutout to [email protected] for catching this in an earlier post.
Given Vicuna was a widely appreciated member of the original Llama series, it’ll be exciting to see this model evolve and adapt with fresh datasets and new training and fine-tuning approaches.
Feel free using this megathread to chat about Vicuna and any of your experiences with Vicuna v1.5!
Starting off with Vicuna v1.5
TheBloke is already sharing models!
Vicuna v1.5 GPTQ
7B
13B
Vicuna Model Card
Model Details
Vicuna is a chat assistant fine-tuned from Llama 2 on user-shared conversations collected from ShareGPT.
Developed by: LMSYS
- Model type: An auto-regressive language model based on the transformer architecture
- License: Llama 2 Community License Agreement
- Finetuned from model: Llama 2
Model Sources
- Repository: https://github.com/lm-sys/FastChat
- Blog: https://lmsys.org/blog/2023-03-30-vicuna/
- Paper: https://arxiv.org/abs/2306.05685
- Demo: https://chat.lmsys.org/
Uses
The primary use of Vicuna is for research on large language models and chatbots. The target userbase includes researchers and hobbyists interested in natural language processing, machine learning, and artificial intelligence.
How to Get Started with the Model
- Command line interface: https://github.com/lm-sys/FastChat#vicuna-weights
- APIs (OpenAI API, Huggingface API): https://github.com/lm-sys/FastChat/tree/main#api
Training Details
Vicuna v1.5 is fine-tuned from Llama 2 using supervised instruction. The model was trained on approximately 125K conversations from ShareGPT.com.
For additional details, please refer to the “Training Details of Vicuna Models” section in the appendix of the linked paper.
Evaluation Results
Vicuna is evaluated using standard benchmarks, human preferences, and LLM-as-a-judge. For more detailed results, please refer to the paper and leaderboard.
I guess that’s kind of my problem. :) With 64GB RAM you can run 40, 65, 70B parameter quantized models pretty casually. It’s not super fast, but I don’t really have a specific “use case” so something like 600ms/token is acceptable. That being the case, how do I get excited about a 7B or 13B? It would have to be doing something really special that even bigger models can’t.
I assume they’ll be working on a Vicuna-70B 1.5 based on LLaMA to so I’ll definitely try that one out when it’s released assuming it performs well.