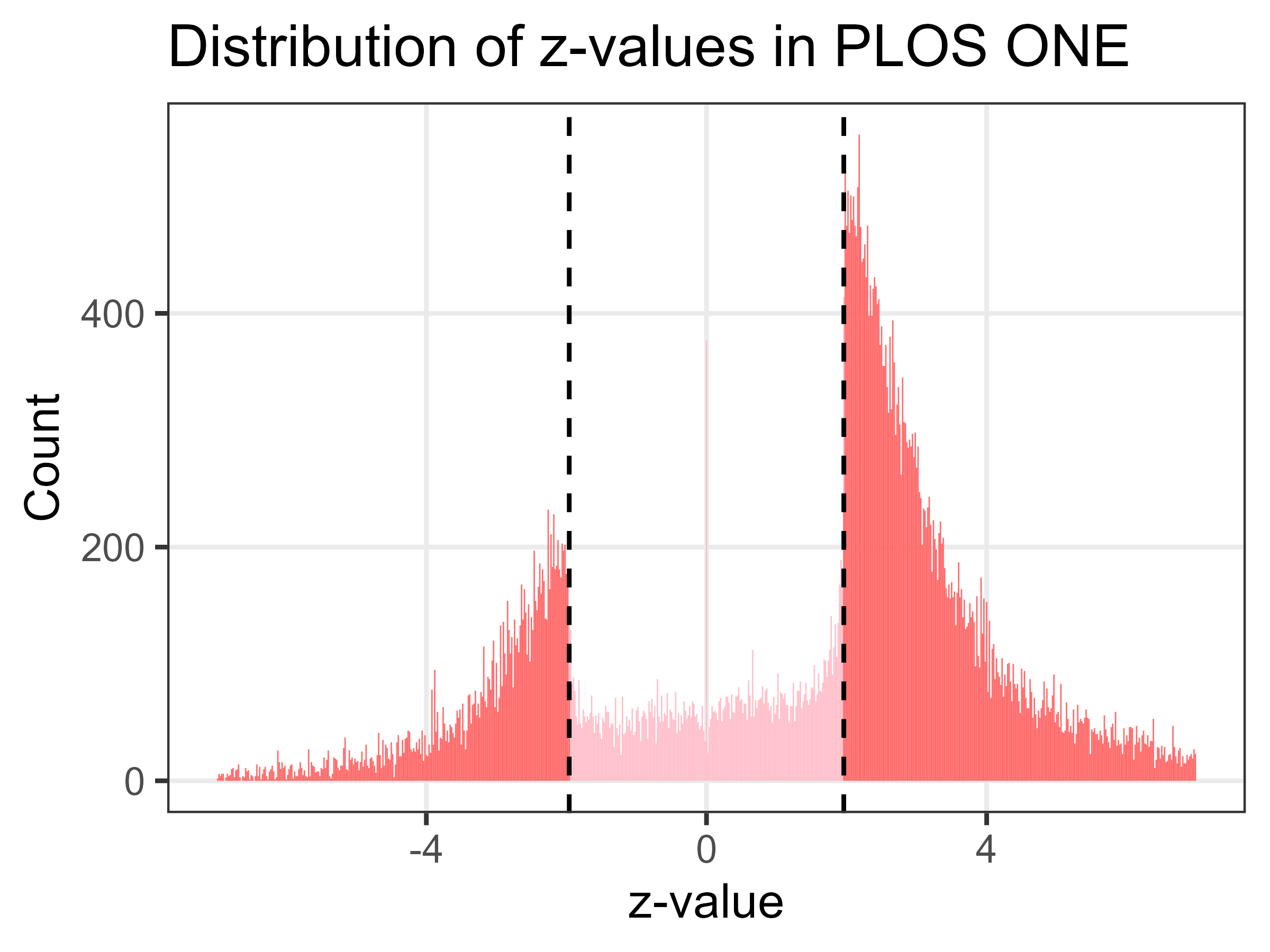
The two large spikes in Z-values are just below and above the statistically significant threshold of ± 1.96, corresponding to a p-value of less than 0.05. The plot looks like a Normal distribution that’s caved in.
From my limited statistical understanding, the Z value measures standard deviations compared to the null hypothesis. This page on statistical analysis says:
Often, you will run one of the pattern analysis tools, hoping that the z-score and p-value will indicate that you can reject the null hypothesis
To reject the null hypothesis, you must make a subjective judgment regarding the degree of risk you are willing to accept for being wrong (for falsely rejecting the null hypothesis). Consequently, before you run the spatial statistic, you select a confidence level.
So from that, I understand the takeaway from the Z value graph is that if researchers are truly willing to publish studies which don’t reach a definitive conclusion, then the huge gap in the middle should be filled in. But it’s not.
And the danger is that valuable data from studies straddling the arbitrary p=0.05 line is simply being discarded by researchers, before ever reaching the journal. Such data – while not conclusive on its own – could have been aggregated in a metastudy to prove or disprove the effectiveness of medicines and procedures that have non-obvious or long-term impacts. That is a loss to all of humanity.
A while ago, I read a book about how researchers inadvertently misuse statistical tests, along with how to understand what statistics can and cannot do, from the perspective of scientists who will have to work with datasets. It’s not terribly long, and is accessible with no prerequisite of any statistical experience. https://nostarch.com/statsdonewrong
When I was in academia, I always thought there should be a journal for publishing things that go wrong or do not work. I can only imagine there are some experiments that were repeated many times in human history because no one published that they did not work.
I can’t tell you how many times I had some exciting idea, dug around in the literature, found someone 10, 20, even 30 years ago who’d published promising work along exactly the line I was thinking, only to completely abandon the project after one or two publications. I’ve come to see that pattern as “this didn’t actually work, and the first paper was probably bullshit.”
It’s really hard to write an interesting paper based on “this didn’t work,” unless you can follow up to the point where you can make a positive statement of why it didn’t work, and at that point, you’re going to write a paper based on the positive conclusion and demote the negative finding to some kind of control data. You have to have the luxury of time, resources, and interest to go after that positive statement, and that’s usually incompatible with professional development.
I agree with you. My point is that we should normalize writing a paper where you report that the experiments and/or the hypothesis itself did not work. Later, someone (just like you, in your example) may find the paper and realize they did not try this and that. It is knowledge that can be built upon.
“We tried this and got nothing,” is not really knowledge that can be built on. It might be helpful if you say it to a colleague at a conference, but there’s no way for a reader to know if you’re an inept experimenter, got a bad batch of reagents or specimens, had a fundamentally flawed hypothesis, inadequate statistical design, or neglected to control for some secondary phenomenon. You have to do extra work and spend extra money to prove out those possibilities to give the future researcher grounds for thinking up that thing you didn’t try, and you’ve probably already convinced yourself that it’s not going to be a productive line of work.
It might be close if the discussion section of those “This project didn’t really work, but we spent a year on it and have to publish something” papers would include their negative speculation that the original hypothesis won’t work, or the admission that they started on hypothesis H0, got nowhere, and diverted to H1 to salvage the effort, but that takes a level of humility that’s uncommon in faculty. And sometimes you don’t make the decision not to pursue the work until the new grad student can’t repeat any of the results of that first paper. That happens with some regularity and might be worth noting, if only as a footnote or comment attached to the original paper. Or for journals to do a 5-10 year follow-up on each paper just asking whether the authors are still working on the topic and why. “Student graduated and no one else was interested” is a very different reason than “marginal effect size so switched models.”
but there’s no way for a reader to know if you’re an inept experimenter, got a bad batch of reagents or specimens, had a fundamentally flawed hypothesis, inadequate statistical design, or neglected to control for some secondary phenomenon.
I agree, to the extent that single, poor dataset can’t draw useful conclusions. But after (painstakingly) controlling for issues with this dataset and from lots of other similar datasets, there can still be some value extracted from a meta-analysis.
The prospect that someone might one day later incorporate your data into a meta-analysis and at least justify a follow-up, more controlled study, should be sufficient to tip the scale toward publishing more studies and their datasets. I’m not saying hot garbage should be sent to journals, but whatever can be prepared for publishing ought to be.
My understanding – again, just from that book; I’ve never worked in academia – is that some journals now have a procedure for “registering” a study before it happens. That way, the study’s procedure will have been pre-vetted and the journal commits to – and the researchers promise to – publish the data irrespective of any conclusive results. Not perfect, but could certainly help.
the danger is that valuable data from studies straddling the arbitrary p=0.05 line is simply being discarded by researchers
Or maybe experimenters are opting to do further research themselves rather than publish ambiguous results. If you aren’t doing MRI or costly field work, fine tuning your experimental design to get a conclusive result is a more attractive option than publishing a null result that could be significant, or a significant result that you fear might need retracting later.
maybe experimenters are opting to do further research themselves rather than publish ambiguous results
While this might seem reasonable at first, I feel it is at odds with the current state of modern science, where results are no longer the product of individuals like Newton or the Curie’s, but rather whole teams and even organizations, working across universities and across/out of this world. The thought of hoarding a topic to oneself until it’s ripe seems more akin to commercial or military pursuits rather than of academia.
fine tuning your experimental design to get a conclusive result is a more attractive option than publishing a null result that could be significant
I’m not sure I agree. Science is constrained by human realities, like funding, timelines, and lifespans. If researchers are collecting grants for research, I think it’s fair for the benefactors to expect the fruits of the investment – in the form of published data – even if it’s not perfect and conclusory or even if the lead author dies before the follow-up research is approved. Allowing someone else to later pick up the baton is not weakness but humility.
In some ways, I feel that “publish or perish” could actually be a workable framework if it had the right incentives. No, we don’t want researchers torturing the data until there’s a sexy conclusion. But we do want researchers to work together, either in parallel for a shared conclusion, or by building on existing work. Yes, we want repeat experiments to double check conclusions, because people make mistakes. No, we don’t want ten research groups fighting against each other to be first to print, wasting nine redundant efforts.
or a significant result that you fear might need retracting later.
I’m not aware of papers getting retracted because their conclusion was later disproved, but rather because their procedure was unsound. Science is a process, honing towards the truth – whatever it may be – and accepting its results, or sometimes its lack of results.
I mean I’m speaking from first hand experience in academia. Like I mentioned, this obviously isn’t the case for people running prohibitively costly experiments, but is absolutely the case for teams where acquiring more data just means throwing a few more weeks of time at the lab, the grunt work is being done by the students usually anyways. There are a lot more labs in existence that consist of just a PI and 5-10 grad students/post-docs than there are mega labs working cern.
There were a handful of times I remember rerunning an experiment that was on the cusp, either to solidify a result or to rule out a significant finding that I correctly suspected was just luck - what is another 3 weeks of data collection when you are spending up to a year designing/planning/iterating/writing to get the publication?

{kind=link}
The linked tweet in turn links to Adrian Barnett’s blog post: https://medianwatch.netlify.app/post/z_values/
From my limited statistical understanding, the Z value measures standard deviations compared to the null hypothesis. This page on statistical analysis says:
So from that, I understand the takeaway from the Z value graph is that if researchers are truly willing to publish studies which don’t reach a definitive conclusion, then the huge gap in the middle should be filled in. But it’s not.
And the danger is that valuable data from studies straddling the arbitrary p=0.05 line is simply being discarded by researchers, before ever reaching the journal. Such data – while not conclusive on its own – could have been aggregated in a metastudy to prove or disprove the effectiveness of medicines and procedures that have non-obvious or long-term impacts. That is a loss to all of humanity.
A while ago, I read a book about how researchers inadvertently misuse statistical tests, along with how to understand what statistics can and cannot do, from the perspective of scientists who will have to work with datasets. It’s not terribly long, and is accessible with no prerequisite of any statistical experience. https://nostarch.com/statsdonewrong
EDIT: the author of that book has published its entire text as a website: https://www.statisticsdonewrong.com
When I was in academia, I always thought there should be a journal for publishing things that go wrong or do not work. I can only imagine there are some experiments that were repeated many times in human history because no one published that they did not work.
I can’t tell you how many times I had some exciting idea, dug around in the literature, found someone 10, 20, even 30 years ago who’d published promising work along exactly the line I was thinking, only to completely abandon the project after one or two publications. I’ve come to see that pattern as “this didn’t actually work, and the first paper was probably bullshit.”
It’s really hard to write an interesting paper based on “this didn’t work,” unless you can follow up to the point where you can make a positive statement of why it didn’t work, and at that point, you’re going to write a paper based on the positive conclusion and demote the negative finding to some kind of control data. You have to have the luxury of time, resources, and interest to go after that positive statement, and that’s usually incompatible with professional development.
I agree with you. My point is that we should normalize writing a paper where you report that the experiments and/or the hypothesis itself did not work. Later, someone (just like you, in your example) may find the paper and realize they did not try this and that. It is knowledge that can be built upon.
“We tried this and got nothing,” is not really knowledge that can be built on. It might be helpful if you say it to a colleague at a conference, but there’s no way for a reader to know if you’re an inept experimenter, got a bad batch of reagents or specimens, had a fundamentally flawed hypothesis, inadequate statistical design, or neglected to control for some secondary phenomenon. You have to do extra work and spend extra money to prove out those possibilities to give the future researcher grounds for thinking up that thing you didn’t try, and you’ve probably already convinced yourself that it’s not going to be a productive line of work.
It might be close if the discussion section of those “This project didn’t really work, but we spent a year on it and have to publish something” papers would include their negative speculation that the original hypothesis won’t work, or the admission that they started on hypothesis H0, got nowhere, and diverted to H1 to salvage the effort, but that takes a level of humility that’s uncommon in faculty. And sometimes you don’t make the decision not to pursue the work until the new grad student can’t repeat any of the results of that first paper. That happens with some regularity and might be worth noting, if only as a footnote or comment attached to the original paper. Or for journals to do a 5-10 year follow-up on each paper just asking whether the authors are still working on the topic and why. “Student graduated and no one else was interested” is a very different reason than “marginal effect size so switched models.”
I agree, to the extent that single, poor dataset can’t draw useful conclusions. But after (painstakingly) controlling for issues with this dataset and from lots of other similar datasets, there can still be some value extracted from a meta-analysis.
The prospect that someone might one day later incorporate your data into a meta-analysis and at least justify a follow-up, more controlled study, should be sufficient to tip the scale toward publishing more studies and their datasets. I’m not saying hot garbage should be sent to journals, but whatever can be prepared for publishing ought to be.
My understanding – again, just from that book; I’ve never worked in academia – is that some journals now have a procedure for “registering” a study before it happens. That way, the study’s procedure will have been pre-vetted and the journal commits to – and the researchers promise to – publish the data irrespective of any conclusive results. Not perfect, but could certainly help.
It is a good idea, it just needs to be the norm which it isn’t at the moment.
Or maybe experimenters are opting to do further research themselves rather than publish ambiguous results. If you aren’t doing MRI or costly field work, fine tuning your experimental design to get a conclusive result is a more attractive option than publishing a null result that could be significant, or a significant result that you fear might need retracting later.
While this might seem reasonable at first, I feel it is at odds with the current state of modern science, where results are no longer the product of individuals like Newton or the Curie’s, but rather whole teams and even organizations, working across universities and across/out of this world. The thought of hoarding a topic to oneself until it’s ripe seems more akin to commercial or military pursuits rather than of academia.
But that gut feeling aside, withholding data does have a cost, be it more pedestrians being hit by cars or bunk science taking longer to disprove. At some point, a prolonged delay or shelving data outright becomes unethical.
I’m not sure I agree. Science is constrained by human realities, like funding, timelines, and lifespans. If researchers are collecting grants for research, I think it’s fair for the benefactors to expect the fruits of the investment – in the form of published data – even if it’s not perfect and conclusory or even if the lead author dies before the follow-up research is approved. Allowing someone else to later pick up the baton is not weakness but humility.
In some ways, I feel that “publish or perish” could actually be a workable framework if it had the right incentives. No, we don’t want researchers torturing the data until there’s a sexy conclusion. But we do want researchers to work together, either in parallel for a shared conclusion, or by building on existing work. Yes, we want repeat experiments to double check conclusions, because people make mistakes. No, we don’t want ten research groups fighting against each other to be first to print, wasting nine redundant efforts.
I’m not aware of papers getting retracted because their conclusion was later disproved, but rather because their procedure was unsound. Science is a process, honing towards the truth – whatever it may be – and accepting its results, or sometimes its lack of results.
I mean I’m speaking from first hand experience in academia. Like I mentioned, this obviously isn’t the case for people running prohibitively costly experiments, but is absolutely the case for teams where acquiring more data just means throwing a few more weeks of time at the lab, the grunt work is being done by the students usually anyways. There are a lot more labs in existence that consist of just a PI and 5-10 grad students/post-docs than there are mega labs working cern.
There were a handful of times I remember rerunning an experiment that was on the cusp, either to solidify a result or to rule out a significant finding that I correctly suspected was just luck - what is another 3 weeks of data collection when you are spending up to a year designing/planning/iterating/writing to get the publication?