

My first experience with Lemmy was thinking that the UI was beautiful, and lemmy.ml (the first instance I looked at) was asking people not to join because they already had 1500 users and were struggling to scale.
1500 users just doesn’t seem like much, it seems like the type of load you could handle with a Raspberry Pi in a dusty corner.
Are the Lemmy servers struggling to scale because of the federation process / protocols?
Maybe I underestimate how much compute goes into hosting user generated content? Users generate very little text, but uploading pictures takes more space. Users are generating millions of bytes of content and it’s overloading computers that can handle billions of bytes with ease, what happened? Am I missing something here?
Or maybe the code is just inefficient?
Which brings me to the title’s question: Does Lemmy benefit from using Rust? None of the problems I can imagine are related to code execution speed.
If the federation process and protocols are inefficient, then everything is being built on sand. Popular protocols are hard to change. How often does the HTTP protocol change? Never. The language used for the code doesn’t matter in this case.
If the code is just inefficient, well, inefficient Rust is probably slower than efficient Python or JavaScript. Could the complexity of Rust have pushed the devs towards a simpler but less efficient solution that ends up being slower than garbage collected languages? I’m sure this has happened before, but I don’t know anything about the Lemmy code.
Or, again, maybe I’m just underestimating the amount of compute required to support 1500 users sharing a little bit of text and a few images?
Hi, programming.dev owner here. From what I’ve been seeing it’s a lot of memory issues. We were hitting swap which was causing massive disk io. You can see what happened with the disk io immediately after the upgrade to more memory.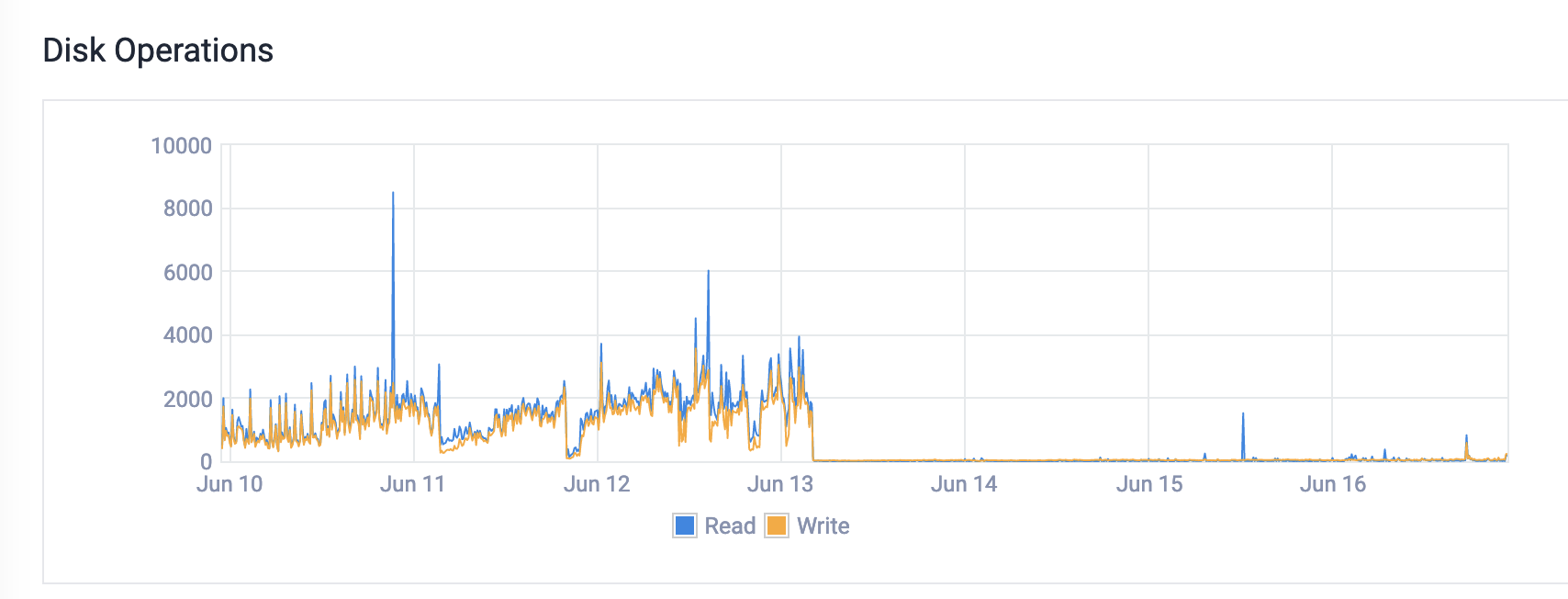 I know at least one reason is being resolved in this PR
I know at least one reason is being resolved in this PR
We were also having issues with the nginx config. There were some really weird settings that I don’t think were necessary. Finally, the federation is quite busy. So if someone subscribes to events from 10 different servers, we pull in every single event, even upvotes. There’s currently a lot of work being done around this stuff.
I don’t think Rust is the problem. I think it’s just a growth thing. Every platform has growth challenges, things grow in ways that you never expect. You might have thought that it was going to be IO constrained due to the federation, but in reality it’s memory constrained because memory is actually the most expensive thing to have on a server. etc.
You mean like coalescing multiple events into a single message, or…? (I don’t know anything about ActivityPub, so apologies if this is a stupid question!)
correct. I’ve been looking for the thread to try and find it for you, but haven’t been having any luck. People have been discussing exactly that though, but it seems like it could cause some problems with vote faking. Anyway, it is being worked on!
Thank you for the insight. Fascinating. Also insane that ever upvote causes a flood of messages being distributed…
Any reason to use nginx versus something like Envoy? Like, I really like nginx, but Envoy’s xDS API is really great for on-the-fly changes. I also think it might scale better and have more relevant default values. I’m just not sure if Lemmy ties into nginx in some way, or if you’re purely using it as a reverse proxy.
I’ll note that most of my Envoy experience is from using it with k8s and a custom ingress controller, where my org handles millions of requests per second (across many Envoy pods). Deploying it standalone might make it less fun.
Nginx is part of the lemmy-ansible install. I’ve never heard of Envoy though. if you’re interested in helping out you can always join the discord. We also set up a matrix room, but it doesn’t have as much discussion in it yet. https://app.element.io/#/room/!hmRRJzTsXkNAGIDXNu:matrix.org