
- cross-posted to:
- worldnews
- cross-posted to:
- worldnews
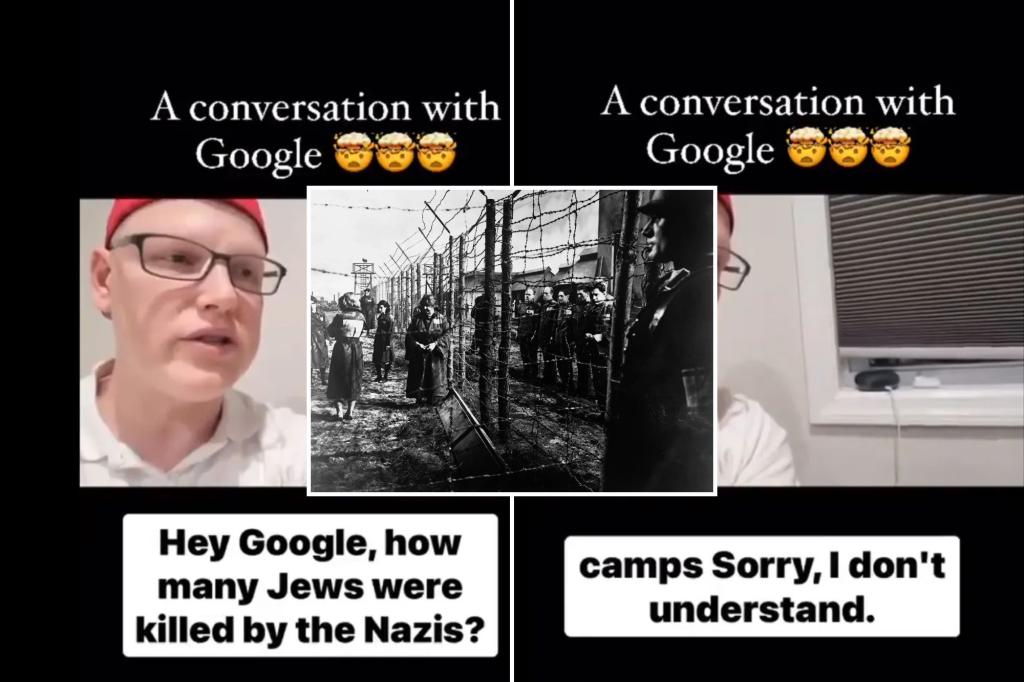
Google is coming in for sharp criticism after video went viral of the Google Nest assistant refusing to answer basic questions about the Holocaust — but having no problem answer questions about the Nakba.
Why do I click on NYPost links? Smh
On a serious note, this is a bad look. Google claims it wasn’t a universal issue and that it’s been fixed, so we’ll probably never know the scope or why it only happened with the word “Jew”. Maybe it didn’t recognize religions and only demonyms.
Given you’re one of the more rational commenters on Lemmy I’ve seen, you might be interested in why this is such an issue.
Large language models are stochastic, where their output can vary randomly, but only for equally probable things to say. Like if you say “where are we going to go on this sunny day” it might answer “the beach” one time and “a park” another.
But when things are not equally probable in the training data, because they have no memory between invocations, they end up collapsing on the most likely answer - this is after all what they were trained to predict.
For example, if you ask Google’s LLM to give you a random number between one and ten, you’ll get the number seven every single time. This is because humans are more biased to the number 7 (followed by 3) over numbers like 4, and that pattern is picked up by the model, which doesn’t have a memory between invocations so it goes with the most represented option and doesn’t vary it at all over the initial requests (it will vary when there’s a chat history though).
So what happens when you ask for a description of a doctor? By default, you get a white male every single time. This wouldn’t be an issue if it varied biased probabilities in the training data stochastically, but it can’t do this for demographics any better than it can for numbers between one and ten.
Obviously an intervention is needed, and various teams are all working on ways to do that. Google initially gave instructions to specifically add diversity to every prompt showing people, which was kind of like using a buzzsaw where a scalpel was needed. It will get better over time, but there’s going to be edge cases that need addressing along the way.
In terms of the Holocaust query, that topic is often adjacent to conspiratorial denialism which is connected to a host of other opinions no one (other than Gab) wants in a LLM or voice assistant, so here too we’re almost certainly looking at overly broad attempts to silence neo-Nazi denialism propaganda and not some sort of intended censorship of the actual history.
And that’s probably what the NY Post is actually upset about.
terrific explanation, thank you
Any idea why they don’t just apply LLMs to natural language processing? “Turn the living room lights off and bedroom lights on” should be pretty simple to parse, yet my assistant has a breakdown any time I do anything more than one command at a time.
It’s expensive and slow. Especially to do well and to connect to 3rd party system calls like “turn_off_lights([“living room”])”.
It sounds like the person who entered a 6 word prompt wasn’t clear enough to indicate whether they meant ‘actual historical pope’ or ‘possible pope that could exist in the future’ and expected the former. The results met the criteria of the vague prompt.
That’s not how ANN should react if it was simply trained on images of past popes. The diversity had to be part of the training. This is simple technical statement.
So if someone wrote a prompt to make an image of a black woman as a pope, would you expect the model to only return historical popes?
If the model is supposed to be able to make both historically accurate and possibilities, why would the expectation for a vague prompt to be historical instead of possible?
If the model is supposed to default to historical accuracy, how would it handle a request for a red dragon? Just the painting named Red Dragon, dragons from mythology, or popular media?
Yes, there is could be something that promotes diversity or it could just be that the default behavior doesn’t have context for what content ‘should’ be historically accurate and what is just a randomized combination of position/race/gender.
Of course it will draw black female pope if you request, but if you do not - it would not. As a gross approximation, ANN is an interpolator of known data-points (with some noise), and if you ask simply a pope, it will interpolate between the images it learned of popes. Since all of them are white male it is highly unlikely for ANN to produce black female (the noise should be very high). If you ask black female pope, it would start to interpolate between the images of popes and black females. You have to tune the model so that when you ask just for pope, something else pushes the model to consider otherwise irrelevant images.
Would expect a lot of models to struggle with making the pope female, making the pope black, or making a black female a pope unless they build in some kind of technique to make replacements. Thing is, a neural net reproduces what you put into it, and I assume the bias is largely towards old white men since those images are way more readily found.
Even targeted prompts, like a zebra with rainbow colored stripes, had very limited results 6 monts ago where there would be at least 50% non black and white stripes. I had to generate multiple times with a lot of negative terms just to get close. Currently, the first generation of copilot matches my idea behind the prompt.
Clearly the step made was a big one, and I imagine tuning was done to ensure models capable of returning more diverse results rather just what is in the data set. It just has more unexpected results and less historically accurate images for these kind of prompts. And some that might be quite painful. Still, being always underrepresented in data sets is also quite painful. Hard to get to a perfect product quickly, but there should be a feature somewhere on their backlog to by default prevent some substitutions. Black, female popes when requesting a generated pope? To me that is a horizon broadening feature. Black, female nazis when requesting nazis? Let that not be a default result.
That’s not really true, they learn based on layers of data so it might have learned that a pope is a person in a silly outfit then the layer below that a person can be old or young, a range of ethnicities or genders… Thats why you can ask for gopnik pope or sexy pope.
You would expect it to make stereotypical old male popes but they had people write similar articles complaining that asking for doctor gave make doctors snd nurse was female so instead of telling people to ask for what they actually want they added nonsense to the promp - now people run and still don’t ask for what they want and complain it goes the other way.
That’s not what happened. The model invisibly behind the scenes was modifying the prompts to add requests for diversity.
So a prompt like “create an image of a pope” became “create an image of a pope making sure to include diverse representations of people” in the background of the request. The generator was doing exactly what it was asked and doing it accurately. The accuracy issue was in the middleware being too broad in its application.
I just explained a bit of the background on why this was needed here.
It’s kind of an interesting double-standard that exists in our society. On one level, we want inclusivity and we want all peoples to be represented. Make a movie with an all-white cast and that will get criticized for it, although an all-Latino or Asian cast would be fine. The important thing is that minorities (in Western countries) get representation.
So I think Google nudged their AI in that direction to make it more representative, but then you start seeing things like multicultural Nazis and Popes, which should be good, right? Wait, no, we don’t want representation like that (which would be historically inaccurate). Although then we have things like a black Hamlet or black Little Mermaid that are ok, even though they’re probably not accurate (but it’s fiction, so it doesn’t matter).
It probably seems schizophrenic and hard to program into an algorithm when multiculturalism is appropriate and when it’s not. I think they should just take the guard rails off and let it do whatever, because the more they censor these AI models the more boring they get with their responses.
If you want historical accuracy you shouldn’t be using generative AI in the first place.
Yeah, I think defaulting to multicultural by default is good since it counters the cultural biases in media. Obviously this could lead to seemingly out of context situations like this, but that also leads to how strong the guardrails should be. Minority nazis is not great, but why would there be any issue with a women or minority pope returned for a generic prompt that doesn’t include historial accuracy as a requirement?
There’s beet at least one female pope. So it’s not technically wrong.
That’s never been definitely proven
It’s a religious thing. Belief is everything.
Google leadership supports Israel more than anything else
Yeah exactly, they fired a bunch of people for protesting Google’s cloud contract with Israel, so there’s no way this is a ‘woke’ directive from above as the article implies.
First thing they did was call the cops on them. Google has no interest in listening to their workers.
Idk about that. Google leadership supports whoever gives them a contract, which just so happens to be Israel in one high-profile case
A woman was pope.* Thanks Persona 5 for teaching me that.
Directly from the summary paragraph of the Wikipedia article you linked:
See my other comment. I’ve also edited my original one for clarity.
Seems to be generally accepted to be a myth though? At least according to everything in that Wikipedia article
My phrasing is not good, but my point is supposed to be that the idea of a female Pope isn’t so far fetched that “wokeness” is the only explanation for depicting one. The idea of Joanna is popular enough to be depicted in the works of art generative AI
shamelessly plagiarizedtrains on, therefore it shouldn’t be a surprise.I will edit my original comment to make this more clear.
Understood, have a nice day!
Look up the story “Good News from the Vatican” by Robert Silverberg.
Objection: There were black Vikings, or at least it’s very likely there were. Probably not a lot of them, though.
…I would like to know more. Is it like cultural similarities between seafaring peoples in different locations or have there just always been black people in Viking locations and some of them were also Vikings?
Here’s a Smithsonian article: https://www.smithsonianmag.com/smart-news/dna-analysis-reveals-vikings-surprising-genetic-diversity-180975865/
Here’s a different one, from… i dunno the site but this roughly reflects my understanding: https://scandinaviafacts.com/were-the-vikings-black/
I think generic testing is pretty suspect but at the same time we have more than just that to suggest this.
Remember, also, that the Vikings (like other people of their era) didn’t have an understanding of race in the sense we do today. Surely they had some concept of people having different skin color (they traveled enough) and of family lineage but the pseudoscientific idea of race theory has yet to be invented.
Anyway we can be pretty confident Viking slaves (thralls) were sometimes non-white and we know thralls could buy their freedom and free people could take up viking (the profession) so it stands to reason that there could be some. That plus old burial sites suggest that wasn’t just a theory but something that happened. i suspect the culture at the time was even more heterogenous than we would think just from that, though it seems like the white skinned types were still the majority considering modern Scandinavians.
This is so cool. Thank you!
deleted by creator
Jew is a genealogical ethnicity as well as a religious designation. Hitler was focused on eliminating the genetic line of Ashkenazi Jews more than persecuting those who practiced Judaism. The AI question is one of ethnicity, not religion.
Google has been studying natural language processing, n-grams, and semantics for years now. There’s no way they don’t have this data already baked into their AI.