
- cross-posted to:
- [email protected]
- [email protected]
- sysadmin
- cross-posted to:
- [email protected]
- [email protected]
- sysadmin
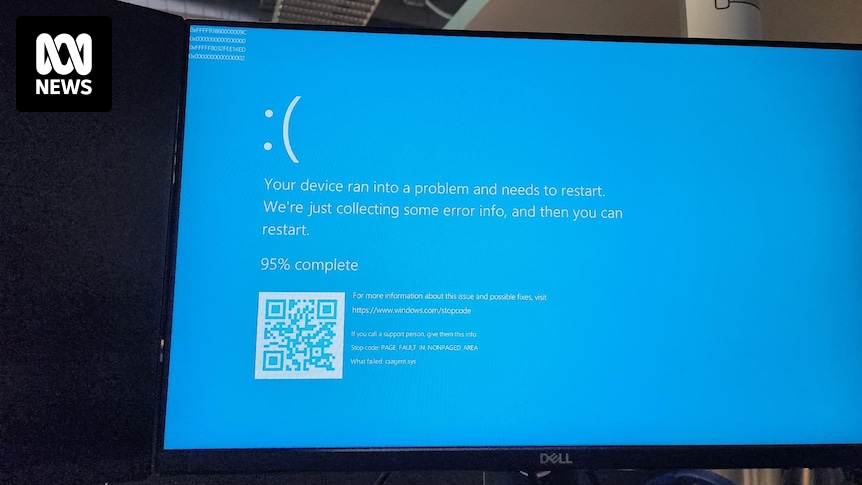
All our servers and company laptops went down at pretty much the same time. Laptops have been bootlooping to blue screen of death. It’s all very exciting, personally, as someone not responsible for fixing it.
Apparently caused by a bad CrowdStrike update.
Edit: now being told we (who almost all generally work from home) need to come into the office Monday as they can only apply the fix in-person. We’ll see if that changes over the weekend…
Reading into the updates some more… I’m starting to think this might just destroy CloudStrike as a company altogether. Between the mountain of lawsuits almost certainly incoming and the total destruction of any public trust in the company, I don’t see how they survive this. Just absolutely catastrophic on all fronts.
If all the computers stuck in boot loop can’t be recovered… yeah, that’s a lot of cost for a lot of businesses. Add to that all the immediate impact of missed flights and who knows what happening at the hospitals. Nightmare scenario if you’re responsible for it.
This sort of thing is exactly why you push updates to groups in stages, not to everything all at once.
Looks like the laptops are able to be recovered with a bit of finagling, so fortunately they haven’t bricked everything.
And yeah staged updates or even just… some testing? Not sure how this one slipped through.
I’d bet my ass this was caused by terrible practices brought on by suits demanding more “efficient” releases.
“Why do we do so much testing before releases? Have we ever had any problems before? We’re wasting so much time that I might not even be able to buy another yacht this year”
At least nothing like this happens in the airline industry
Certainly not! Or other industries for that matter. It’s a good thing executives everywhere aren’t just concentrating on squeezing the maximum amount of money out of their companies and funneling it to themselves and their buddies on the board.
Sure, let’s “rightsize” the company by firing 20% of our workforce (but not management!) and raise prices 30%, and demand that the remaining employees maintain productivity at the level it used to be before we fucked things up. Oh and no raises for the plebs, we can’t afford it. Maybe a pizza party? One slice per employee though.
One of my coworkers, while waiting on hold for 3+ hours with our company’s outsourced helpdesk, noticed after booting into safe mode that the Crowdstrike update had triggered a snapshot that she was able to roll back to and get back on her laptop. So at least that’s a potential solution.
Agreed, this will probably kill them over the next few years unless they can really magic up something.
They probably don’t get sued - their contracts will have indemnity clauses against exactly this kind of thing, so unless they seriously misrepresented what their product does, this probably isn’t a contract breach.
If you are running crowdstrike, it’s probably because you have some regulatory obligations and an auditor to appease - you aren’t going to be able to just turn it off overnight, but I’m sure there are going to be some pretty awkward meetings when it comes to contract renewals in the next year, and I can’t imagine them seeing much growth
Nah. This has happened with every major corporate antivirus product. Multiple times. And the top IT people advising on purchasing decisions know this.
Yep. This is just uninformed people thinking this doesn’t happen. It’s been happening since av was born. It’s not new and this will not kill CS they’re still king.
At my old shop we still had people giving money to checkpoint and splunk, despite numerous problems and a huge cost, because they had favourites.
Don’t most indemnity clauses have exceptions for gross negligence? Pushing out an update this destructive without it getting caught by any quality control checks sure seems grossly negligent.
deleted by creator
Can’t; the project manager ate all the crayons
Why is it bad to do on a Friday? Based on your last paragraph, I would have thought Friday is probably the best week day to do it.
Most companies, mine included, try to roll out updates during the middle or start of a week. That way if there are issues the full team is available to address them.
deleted by creator
And hence the term read-only Friday.
Was it not possible for MS to design their safe mode to still “work” when Bitlocker was enabled? Seems strange.
I’m not sure what you’d expect to be able to do in a safe mode with no disk access.
Or someone selected “env2” instead of “env1” (#cattleNotPets names) and tested in prod by mistake.
Look, it’s a gaffe and someone’s fired. But it doesn’t mean fuck ups are endemic.
I think you’re on the nose, here. I laughed at the headline, but the more I read the more I see how fucked they are. Airlines. Industrial plants. Fucking governments. This one is big in a way that will likely get used as a case study.
The London Stock Exchange went down. They’re fukd.
Yeah saw that several steel mills have been bricked by this, that’s months and millions to restart
Got a link? I find it hard to believe that a process like that would stop because of a few windows machines not booting.
That’s the real kicker.
Those machines should be airgapped and no need to run Crowdstrike on them. If the process controller machines of a steel mill are connected to the internet and installing auto updates then there really is no hope for this world.
But daddy microshoft says i gotta connect the system to the internet uwu
No, regulatory auditors have boxes that need checking, regardless of the reality of the technical infrastructure.
I work in an environment where the workstations aren’t on the Internet there’s a separate network, there’s still a need for antivirus and we were hit with bsod yesterday
I don’t know how to tell you this, but…
There is no unsafer place than isolated network. AV and xdr is not optional in industry/healthcare etc.
There are a lot of heavy manufacturing tools that are controlled and have their interface handled by Windows under the hood.
They’re not all networked, and some are super old, but a more modernized facility could easily be using a more modern version of Windows and be networked to have flow of materials, etc more tightly integrated into their systems.
The higher precision your operation, the more useful having much more advanced logs, networked to a central system, becomes in tracking quality control.
Imagine if after the fact, you could track a set of .1% of batches that are failing more often and look at the per second logs of temperature they were at during the process, and see that there’s 1° temperature variance between the 30th to 40th minute that wasn’t experienced by the rest of your batches. (Obviously that’s nonsense because I don’t know anything about the actual process of steel manufacturing. But I do know that there’s a lot of industrial manufacturing tooling that’s an application on top of windows, and the higher precision your output needs to be, the more useful it is to have high quality data every step of the way.)
Testing in production will do that
Not everyone is fortunate enough to have a seperate testing environment, you know? Manglement has to cut cost somewhere.
Manglement is the good term lmao
Don’t we blame MS at least as much? How does MS let an update like this push through their Windows Update system? How does an application update make the whole OS unable to boot? Blue screens on Windows have been around for decades, why don’t we have a better recovery system?
Crowdstrike runs at ring 0, effectively as part of the kernel. Like a device driver. There are no safeguards at that level. Extreme testing and diligence is required, because these are the consequences for getting it wrong. This is entirely on crowdstrike.
This didn’t go through Windows Update. It went through the ctowdstrike software directly.