There are a couple I have in mind. Like many techies, I am a huge fan of RSS for content distribution and XMPP for federated communication.
The really niche one I like is S-expressions as a data format and configuration in place of json, yaml, toml, etc.
I am a big fan of Plaintext formats, although I wish markdown had a few more features like tables.
ISO 8601 date format. Not because it’s from a standards body, but because it’s simple, sensible, clearly defined, easy to recognize, and very effective.
Date field placement in any order other than most-significant-digits-first is not only counterintuitive, but needlessly complicated to work with. Omitting critical information like the century is ambiguous and confusing.
We don’t live in isolated villages any more. Mixing and matching those problems by accepting all the world’s various regional and personal date styles, especially with no reliable indication of which ones apply in any given case, leads to the hodgepodge of error-prone date madness that we have today.
The 2024-09-02 format should be taught in schools and required in official documents. Let the antiquated date styles fall into disuse outside of art and personal correspondence, like cursive writing.
And it can be sorted alphabetically in all software. That’s a pretty big advantage when handling files on a computer
I had the fortune of being hired to build up from zero my department, and one of the first “rules” I made was all dates are ISO-8601 and now every process runs with 8601, if you use anything different your code is going to fail eventually when it finds another column date in 8601.
I love this standard. If you dig deeper into it, the standard also covers a way to express intervals and periods. E.g. “P1Y2M10DT2H30M” represents one year, 2 months, 10 days, 2 hours and 30 mins.
I recall once using the standard when writing a cron-style scheduler.
I also like the POSIX “seconds since 1970” standard, but I feel that should only be used in RAM when performing operations (time differences in timers etc.). It irks me when it’s used for serialising to text/JSON/XML/CSV.
Also: Does Excel recognise a full ISO8601 timestamp yet?
I also like the POSIX “seconds since 1970” standard, but I feel that should only be used in RAM when performing operations (time differences in timers etc.). It irks me when it’s used for serialising to text/JSON/XML/CSV.
I’ve seen bugs where programmers tried to represent date in epoch time in seconds or milliseconds in json. So something like “pay date” would be presented by a timestamp, and would get off-by-one errors because whatever time library the programmer was using would do time zone conversions on a timestamp then truncate the date portion.
If the programmer used ISO 8601 style formatting, I don’t think they would have included the timepart and the bug could have been avoided.
Use dates when you need dates and timestamps when you need timestamps!
Thats an issue with the time library, not with timestamps. Actually timestamps are always in UTC, you need to do the conversion to your local time when displaying the value. There should be no possible off-by-one errors, unless you are doing something really wrong.
RFC 3339 is a simplified profile of 8601 that only covers YYYY-MM-DD style formatting, if you only ever use that format and avoid the things like “2024-W36” they’re mostly interchangeable.
The week-of-year is far more relevant in Western Europe, and is used quite a bit in business. I have a Junghans watch that has a week complication.
It’s an important format outside of the US, and gives ISO-8601 an edge as a standard of conformance.
For the newbies: RFC 3339 vs ISO 8601. Bookmark this site.
That looks like an interesting diagram, but the text in it renders too small to read easily on the screen I’m using, and trying to open it leads to a javascript complaint and a redirect that activates before I can click to allow javascript. If it’s yours, you might want to look in to that.
The table below works, though. Thanks for the link.
Alas it’s not my site (and I think it’s meant to be read on a desktop screen), so I can’t fix it.
7 digit years feels way to optimistic, but I’ll be rooting for us.
I arrived to manage releases in a company, the previous manager named releases as “release04092016”, as USA standard. My first recommendation was to name releases as “releaseyyyymmdd” so “release20160409”. I was asked by another manager why to change that, so I showed her a sorted list of releases “git branches” and asked her, can you tell me there when was the last release? (a very common question) Of course, to find the last release you need to check the whole list because the mmddyyyy order is useless. The answer with yyyymmdd was immediate, just look at the last row.
Some countries already use it officially too :)
Also, you can sort by ascending file names
The year is the information that most of the time is the least significant in a date, in day to day use.
DDMMYY is perfect for daily usage.
DDMMYY is perfect for daily usage.
Except that DDMMYY has the huge ambiguity issue of people potentially interpreting it as MMDDYY. And it’s not straight sortable.
My team switched to using YYYY-MM-DD in all our inner communication and documents. The “daily date use” is not the issue you think it is.
Except that DDMMYY has the huge ambiguity issue of people potentially interpreting it as MMDDYY.
Yes and YYYY-MM-DD can potentially be interpreted as YYYY-DD-MM. So that is an zero argument.
I never said that the date format should never used, just that significants is a arbitrary value, what significant means depends on the context. If YYYY-MM-DD would be so great in everyday use then more or even most people would use it, because people, in general, tend to do things that make their life easier.
There is no superior date format, there are just date format that are better for specific use cases.
My team switched to using YYYY-MM-DD in all our inner communication and documents
That is great for your team, but I don’t think that your team has a size large enough to have any kind of statistically relevance at all. So it is a great example for a specific use case but not an argument for general use at all.
Yes and YYYY-MM-DD can potentially be interpreted as YYYY-DD-MM. So that is an zero argument.
No country uses “year day month” ordered dates as standard. "Month day year, " on the other hand, has huge use. It’s the conventions that cause the potential for ambiguity and confusion.
That is great for your team, but I don’t think that your team has a size large enough to have any kind of statistically relevance at all. So it is a great example for a specific use case but not an argument for general use at all.
Entire countries, like China, Japan, Korea, etc., use YYYY-MM-DD as their date standard already.
My point was that once you adjust, it actually isn’t painful to use as it first appears it could be, and has great advantages. I didn’t say there wasn’t an adjustment hurdle that many people would bawk at.
https://en.m.wikipedia.org/wiki/List_of_date_formats_by_country
Entire countries, like China, Japan, Korea, etc., use YYYY-MM-DD as their date standard already.
And every person in those countries uses YYYY-MM-DD always in their day to day communication? I really doubt that. I am sure even in those countries most people will still use short forms in different formats.
Yes, and their shorthand versions, like writing 9/4, have the same problem of being ambiguous.
You keep missing the point and moving the goal posts, so I’ll just politely exit here and wish you well. Peace.
I never moved the goalposts, all I always said was that a forced and clunky date format like YYYY-MM-DD will never find broad use or acceptance in the major population of the world. It is not made for easy day to day use.
If it sounded like I moved goalposts, that maybe due to english as a second language. Sorry for that.
But yes, I think we both have made our positions and statements clear, and there is not really a common ground for us. Not because one of us would be right or wrong but because we are not talking about the topic on the same level of abstraction. I talk about it from a social, very down to the ground perspective and you are at least 2 levels of abstraction above that. Nothing wrong with that but we just don’t see the same picture.
And yes using YYYY-MM-DD would be great, I don’t say anything against that on a general level, I just don’t ever see any chance for it used commonly.
So thank you for the great discussion and have a nice day.
Your day to day use isn’t everyone else’s. We use times for a lot more than “I wonder what day it is today.” When it comes to recording events, or planning future events, pretty much everyone needs to include the year. Getting things wrong by a single digit is presented exactly in order of significance in YYYY-MM-DD.
And no matter what, the first digit of a two-digit day or two-digit month is still more significant in a mathematical sense, even if you think that you’re more likely to need the day or the month. The 15th of May is only one digit off of the 5th of May, but that first digit in a DD/MM format is more significant in a mathematical sense and less likely to change on a day to day basis.
For any scheduled date it is irrelevant if you miss it for a day, a month or a year. So from that perspective every part of it is exactly the same, if the date is wrong then it is wrong. You say that it is sorted in the order of most significants, so for a date it is more significant if it happend 1024, 2024 or 9024? That may be relevant for historical or scientific purposes but not much people need that kind of precision. Most people use calendars for stuff days or month ahead or below, not years or decades.
If I get my tax bill, I don’t care for the year in the date because I know that the government wants the money this year not next or on ten. If I have a job interview, I don’t care for the year, the day and months is what is relevant. It has a reason why the year is often removed completely when dates are noted or made. Because it Is obvious.
Yes I can see why YYYY-MM-DD is nice for stuff like archiving purposes, it makes sorting and grouping very easy but there they already use the best system for the job.
For digital documents I would say that date and time information should be stored in a defined computer readable standard so that the document viewer can render or use it in any way needed. That could be swatch internet time as far as I care because hopefully I would never look at the raw data at all.
You say that it is sorted in the order of most significants, so for a date it is more significant if it happend 1024, 2024 or 9024?
Most significant to least significant digit has a strict mathematical definition, that you don’t seem to be following, and applies to all numbers, not just numerical representations of dates.
And most importantly, the YYYY-MM-DD format is extensible into hh:mm:as too, within the same schema, out to the level of precision appropriate for the context. I can identify a specific year when the month doesn’t matter, a specific month when the day doesn’t matter, a specific day when the hour doesn’t matter, and on down to minutes, seconds, and decimal portions of seconds to whatever precision I’d like.
Ok, then I am sure we will all be using that very soon, because abstract mathematic definitions always map perfectly onto real world usage and needs.
It is not that I don’t follow the mathematic definition of significance, it is just invalid for the view and scope of the argument that I make.
YYYY-MM-DD is great for official documents but not for common use. People will always trade precision for ease of use, and that will never change. And in most cases the year is not relevant at all so people will omit it. Other big issue: People tend to write like they talk and (as far as I know) nobody says the year first. That’s exactly why we have DD-MM and MM-DD
YYYY-MM-DD will only work in enforced environments like official documents or workspaces, because everywhere else people will use shortcuts. And even the best mathematic definition of the world will not change that.
IPv6. Stop engineering IoT junk on single-stack IPv4, you dipshits.
Ogg Opus. It’s superior to everything in every way. It’s free and there is absolutely no reason to not support it. It blows my mind that MPEG 1.0 Layer III is still so dominant.
It blows my mind that MPEG 1.0 Layer III is still so dominant.
Count the number of devices in use today that will never support Opus, and it might not blow your mind any longer. Also, AFAIK, the reference implementation still doesn’t implement full functionality on hardware that lacks a floating point unit.
These things take time.
I remember using Xiph’s integer implementation of Ogg Vorbis on my Nokia N-Gage (Symbian S60). I wonder if it’s not a priority for Opus. IIRC, Opus is floats all the way down.
update: it exists.
https://wiki.xiph.org/OpusFAQ#Is_there_a_fixed-point_implementation?
I remember trying to understand Vorbis fixed point codebase, it was completely bonkers, the three of us on this task couldn’t even draw a rough control flow diagram.
IPv6. Stop engineering IoT junk on single-stack IPv4, you dipshits.
Amen
Out of curiosity, why ogg as opposed to other containers? What advantages does it have?
Definitely agree on the Opus part, but I am very ignorant on the ogg container.
Large ISPs still don’t support it. It’s a fucking travesty.
I setup my opnsense firewall for IPv6 recently with Spectrum as an ISP. I followed this howto from The Other Site:
Even as someone who has a background in networking, I’d have no idea how to figure some of that stuff out on my own (besides reading a whole lot and trying shit that will probably break my network for a weekend). And whatever else you might say about Spectrum, they have one of the saner ways to implement it; no 6to4 or PPPoEv6 or any of that nonsense.
I did set the config for a /54, but Spectrum still gave me a /64. Which you can’t subnet in IPv6. Boo.
Oh, and I’m not 100% sure if the prefix is static or not. There’s no good reason that it should change, except to make self-hosting more difficult, but I have a feeling I’ll see it change at some point.
So basically, if this is confusing and limiting for power users, how are average home users supposed to do it?
There are some standardization things that could make things easier, but ISPs seem to be doing everything they can to make this as painful as possible. Which is to their own detriment. Sticking to IPv4 makes their networks more expensive, less reliable, and slower.
Love, love, opus. It’s a fantastic format.
The metric system, f*ck the imperial system. Every scientist sticks to the metric system, and why are people even still having an imperial system, with outdated measurements like stones for weight blows my mind.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that, we don’t need another hard to convert temperature measurement.
You are allowed to say fuck here.
Imperial is used in thermodynamics industries because the calculations work out better.
Also f*ck Fahrenheit, we have Celsius and Kalvin for that,
Who is Kalvin? Did you mean kelvin?
One drawback of celsius/centigrade is that its degrees are so coarse that weather reports / ambient temperature readings end up either inaccurate or complicated by floating point numbers. I’m on board with using it, but I won’t pretend it’s strictly superior.
A degree Celsius is not coarse and does not require decimals in weather reports, and I suspect only a person who has never lived in a Celsius-using country could make such silly claims.
A degree Celsius is not coarse and does not require decimals
Consider that even if the difference between 15° and 16°C is not significant to you, it very well might be to other people. (Spoiler: it is.)
I suspect only a person who has never lived in a Celsius-using country could make such silly claims.
Then your suspicions are leading you astray.
They didn’t say a difference of 1K isn’t significant but the difference of 0.1K isn’t.
And since the supposed advantage of Fahrenheit is that it better reflects typical ambient temperatures, we have to consider relevance for average people. Hardly anyone will feel a difference of 0.1K.
That’s why European weather reports usually show full degrees. And also our fridges show full degrees.
What about thermostats for homes? I can absolutely feel a 2 deg F difference
I use °C and I feel the need to use the places after the decimal. Also, I feel nothing wrong about it.
Also, I use °F for body temperature measurement and need to use the places after the decimal and feel fine with it.
Also, when using °C for body temperature, I still require the same number of decimal places as I require for °F.
I am not saying that °F is not useful, but I am invalidating your argument.
Also whole degrees.edit: no, that’s wrong, there are thermostats that allow 1/10th of degrees (I only have old manual ones). Still, you probably are not able to tell the difference between 20 and 20.1 °C. Humidity is far more relevant.A difference of 2 °F is 1.1 °C…
I’ll fight you on fahrenheit. It’s very good for weather reporting. 0° being “very cold” and 100° being “very hot” is intuitive.
0 degrees Celsius, the water is freezing, 100 degrees Celsius, the water is boiling. Celsius has a direct link to Kelvin, and Kelvin is the SI unit for measurement temperatures.
Asterisk: At 1 atmosphere of pressure. Lots of people forget that part.
What do I care about water? I’m not dressing water for the weather, I’m dressing me.
deleted by creator
Are you not made primarily of water?
Knowing whether it may snow or rain depending on whether you are below or above 0 is very useful though. 0 and 100 are only intuitive because you’re used to those numbers. -20 bring very cold and 40 being very hot is just as easy.
0° being “very cold” and 100° being “very hot” is intuitive.
As someone who’s not used to Fahrenheit I can tell you there’s nothing intuitive about it. How cold is “very cold” exactly? How hot is “very hot” exactly? Without clear references all the numbers in between are meaningless, which is exactly how I perceive any number in Fahrenfeit. Intuitive means that without knowing I should have an intuitive perception, but really there’s nothing to go on. I guess from your description 50°F should mean it’s comfortable? Does that mean I can go out in shorts and a t-shirt? It all seems guesswork.
About the only useful thing I see is that 100 Fahrenheit is about body temperature. Yeah, that’s about the only nice thing I can say about Fahrenheit. All temperature scales are arbitrary, but since our environment is full of water, one tied to the phase changes of water around the atmospheric pressure the vast majority of people experience just makes more sense.
All temperature scales are arbitrary, but since our environment is full of water, one tied to the phase changes of water around the atmospheric pressure the vast majority of people experience just makes more sense.
But when it comes to weather, the boiling point of water is not a meaningful point of reference.
I suppose I’m biased since I grew up in an area where 0-100°F was roughly the actual temperature range over the course of a year. It was newsworthy when we dropped below zero or rose above 100. It was a scale everybody understood intuitively because it aligned with our lived experience.
deleted by creator
But when it comes to weather, the boiling point of water is not a meaningful point of reference.
Well, the freezing point of water is very relevant for weather. If I see that the forecast is -1 degC when it was positive before, I know I will have to watch out for ice on roads.
And the boiling point as the other reference point makes complete sense.
Ours is around 10°C to 40°C, or 15°C to 30°C depending upon your tolerances, so I guess that’s it.
This is strictly untrue for many climates. Where I live in Canada, 0F is average winter day, 100F is record-breaking “I might actually die” levels of heat.
-30C to 30C is not any more complicated or less intuitive than -22F to 86F
For traffic Celsius is more intuitive since temps approaching zero means slippery roads.
You’re long passed that with Fahrenheit. And on a scale from 0 very cold to 100 very hot, 32 doesn’t seem that cold. Until you see the snow outside.
32 isn’t that cold, even if it’s snowing. I do currently live in Minnesota though, so my sense of temperature is much different than someone from somewhere warm.
my sense of temperature is much different than someone from somewhere warm
That’s probably the reason for this preference.
10°C for me means my PC doesn’t heat up the room enough and I need a heater. 32°F and I will be shoving my feet in the heater.
Minnesotan here. Can confirm that 32 is still long-sleeve shirt weather.
I regularly see people here walking into a store from the parking lot in T-shirts, in 32° weather. Wind chill makes a far greater difference. 38° from wind chill is far colder than 32° with no wind.
Ask someone in the north of finland how hot is “very hot”, and how cold is very cold. Then ask the same in middle Africa. Spoiler: it will vary alot.
It’s completely bonkers that JPEG-XL is as good as it is and no one wants to actually implement it into web browsers
Adobe is backing the format, Apple support is coming along, and there are rumors that Apple is switching from HEIC to JPEG XL as a capture format as early as the iPhone 16 coming out in a few weeks. As soon as we have a full blown workflow that can take images from camera to post processing to publishing in JXL, we might see a pretty strong push for adoption at the user side (browsers, websites, chat programs, social media apps and sites, etc.).
Do you know QOI format ? I would appreciate your opinion about it.
QOI is just a format that’s easy for a programmer to get their head around.
It’s not designed for everyday use and hardware optimization like jpeg-xl is.
You’re most likely to see QOI in homebrewed game engines.
To be honest, no. I mainly know about JPEG XL only because I’m acutely aware of the limitations of standard JPEG for both photography and high resolution scanned documents, where noise and real world messiness cause all sorts of problems. Something like QOI seems ideal for synthetic images, which I don’t work with a lot, and wouldn’t know the limitations of PNG as well.
What’s so good about it?
- Existing JPEG files (which are the vast, vast majority of images currently on the web and in people’s own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there’s benefits to adoption, if nothing else for archival and serving old stuff.
- JPEG XL encoding and decoding is much, much faster than pretty much any other format.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
- The format anticipates being useful for both screen and prints. Webp, HEIF, and AVIF are all optimized for screen resolutions, and fail at truly high resolution uses appropriate for prints. The JPEG XL format isn’t ready to replace camera RAW files, but there’s room in the spec to accommodate that use case, too.
It’s great and should be adopted everywhere, to replace every raster format from JPEG photographs to animated GIFs (or the more modern live photos format with full color depth in moving pictures) to PNGs to scanned TIFFs with zero compression/loss.
Existing JPEG files (which are the vast, vast majority of images currently on the web and in people’s own libraries/catalogs) can be losslessly compressed even further with zero loss of quality. This alone means that there’s benefits to adoption, if nothing else for archival and serving old stuff.
Funny thing is, there was talk on the Chrome bug tracker of using just this ability transparently at the HTTP layer (like gzip/brotli compression), but they’re so set on pushing their AVIF format that they backed away from it.
- The format works for both lossy and lossless compression, depending on the use case and need. Photographs can be encoded in a lossy way much more efficiently than JPEG and things like screenshots can be losslessly encoded more efficiently than PNG.
Someone made a fair point that having a format being both lossy and lossless is not necessarily a great idea. If you download a jpeg file you know it will be compressed, if you download png it will be lossless. Shifting through jxl files to check if it’s lossy or not doesn’t sound very fun.
All in all I’m a big supporter of jxl though, it’s one of the only github repos I actively follow.
While I agree that it’s somewhat bad that there is no distinction between lossless and lossy jxl in the file extension, I think it’s really not a big deal compared to the present situation with jpg/png.
The reason being that if you download a png file you have no idea if its been converted from jpg, if it’s a screenshot of a jpg, or if it’s been subjected to lossy reencoding by a tool or a website upload process.
The only thing you can really do to try and see if the file you’ve downloaded has suffered encoding loss is to do an image search on it and see if there are any better quality versions out there. You’d do the exact same thing with a jxl file.
Functionally speaking, I don’t see this as a significant issue.
JPEG quality settings can run a pretty wide gamut, and obviously wouldn’t be immediately apparent without viewing the file and analyzing the metadata. But if we’re looking at metadata, JPEG XL reports that stuff, too.
Of course, the metadata might only report the most recent conversion, but that’s still a problem with all image formats, where conversion between GIF/PNG/JPG, or even edits to JPGs, would likely create lots of artifacts even if the last step happens to be lossless.
You’re right that we should ensure that the metadata does accurately describe whether an image has ever been encoded in a lossy manner, though. It’s especially important for things like medical scans where every pixel matters, and needs to be trusted as coming from the sensor rather than an artifact of the encoding process, to eliminate some types of error. That’s why I’m hopeful that a full JXL based workflow for those images will preserve the details when necessary, and give fewer opportunities for that type of silent/unknown loss of data to occur.
Basically smaller file sizes than JPEG at the same quality and it also automatically loads a lower quality version of the image before it loads a higher quality version instead of loading it pixel by pixel like an image would normally load. Google refuses to implement this tech into Chrome because they have their own avif format, which isn’t bad but significantly outclassed by JPEG-XL in nearly every conceivable metric. Mozilla also isn’t putting JPEG-XL into Firefox for whatever reason. If you want more detail, here’s an eight minute video about it.
I’m under the impression that there’s two reasons we don’t have it in chromium yet:
- Google initially ignored jpeg-xl but then everyone jumped on it and now they feel they have to create a post-hoc justification for not supporting it earlier which is tricky and now they have a sunk cost situation to keep ignoring it
- Google today was burnt by the webp vulnerability which happened because there was only one decoder library and now they’re waiting for more jpeg-xl libraries which have optimizations (which rules out reference implementations), good support (which rules out libraries by single authors), have proven battle-hardening (which will only happen over time) and are written safely to avoid another webp style vulnerability.
Google already wrote the wuffs language which is specifically designed to handle formats in a fast and safe way but it looks like it only has one dedicated maintainer which means it’s still stuck on a bus factor of 1.
Honestly, Google or Microsoft should just make a team to work on a jpg-xl library in wuffs while adobe should make a team to work on a jpg-xl library in rust/zig.
That way everyone will be happy, we will have two solid implementations, and they’ll both be made focussing on their own features/extensions first so we’ll all have a choice among libraries for different needs (e.g. browser lib focusing on fast decode, creative suite lib for optimised encode).
I think I would feel better using JPEG-XL where I currently use WebP. Here’s hoping for wider support.
Good news! I believe the Ladybird Browser intends to include support for JPEG XL.
JSON5. it’s basically just JSON with several QoL improvements, like comments, that make it usable as a format for human consumption (as opposed to a serialization format).
Objects may have a single trailing comma.
I just came.
I love that there’s someone out there who’s that passionate about JSON.
I hate grammers in anything that don’t support trailing commas. It’s even worse when it’s supported in some contexts and not others. Like lists are OK, but not function parameters.
TMI
TIL this exists
ActivityPub :) People spend an incredible amount of time on social media—whether it be Facebook, Instagram, Twitter/X, TikTok, and YouTube—so it’d be nice to liberate that.
I mean, you’re in the right place to advocate for that 😜
i’m a plan 9 from bell labs fan. Imagine how excited I was when wsl used 9P for its plumbing. then they scrapped it all for wsl2.
just, the power they managed to get out of those union mounts… your application wants access to the mouse? sure, here’s a file named “mouse”. it’s got the coordinates in it. you want to draw to the screen? here’s a file called like “bitmap” or whatever, just write to it. you want to start a process on another machine? just cd to it and start the process there. want to have the UI show up on your machine? symlink your bitmap file to that directory.
I also wish early web composability could have stayed and expanded. like, the old vlc embed player, which would just show up in your browser and could play any file inline? great stuff. Imagine if every application composed with everything else, like the android Activity and Intent concepts but for anything, just by virtue of living in the same os. need an image? just ask the os and it will present the user with many ways to procure an image, let the selected one run , and hand you back an image. you don’t even have to care where from. in a way, it’s what the arcan guy is doing with his experiments, although that’s more for stitching together graphical pipelines.
Plan 9 even extended the “everything is a file” philosophy to networking, unlike everybody else that used sockets instead.
Are sockets not files?
They’re “file like” in the sense that they’re exposed as an
fd, but they’re not exposed via the filesystem at all (Unlike e.g. unix sockets), and the existing API is just mapped over the sockets one (i.e.write()instead ofsend(),read()instead ofrecv()). There’s also a difference in how you create them, youopen()a file, butconnect()a socket, etc.(As an aside, it turns out Bash has its own virtual file-based wrapper around sockets, so you can do things like
cata remote port with Bash, something you can do natively in Plan 9)Really it just shows that “everything is a file” didn’t stand up in practice, there’s more stuff that needs special treatment than doesn’t (e.g. Interacting with TTYs also has special APIs). It makes more sense to have a better dedicated API than a generic catch-all one.
Since nobody’s brought it up: MQTT.
It got pigeonholed into IoT world, but it’s a pretty decent event pubsub system. It has lots lf security/encryption options, plus a websocket layer, so you can use it anywhere from devices, to mobile, to web.
As of late last year, RabbitMQ started suporting it as a supported server add-on, so it’s easy to use it to create scalable, event-based systems, including for multiuser games.
I spun up a MQTT/Aedes/MongoDB stack on my network recently for some ESP32 sensors.
Fantastic protocol and super easy to work with!
MQTT is great! There are clients available in Python, JS, etc
I’m currently on the ZeroMQ boat. What made you go to Rabbit Mq? I need the Pair socket for zeroMq for a project.
Installed RabbitMQ for use in Python Celery (for task queue and crontab). Was pleasantly surprised it also offered MQTT support.
Was originally planning on using a third-party, commercial combo websocket/push notification service. But between RabbitMQ/MQTT with websockets and Firebase Cloud Messaging, I’m getting all of it: queuing, MQTT pubsub, and cross-platform push, all for free. 🎉
It all runs nicely in Docker and when time to deploy and scale, trust RabbitMQ more since it has solid cluster support.
Depending where you use it, but often tables are available in markdown.
markdown table x y |markdown|table| |--|---| |x|y|Fixed…cos you could only see rendered and not code.
Oh. Good one. Markdown everywhere. Slack always pissed me off for it’s sub par markdown support.
There is an option in the settings to use markdown formatting. I haven’t tried it but I guess it at least makes formatting less annoying.
It’s a (small, shitty) subset of markdown. Slack formatting just kind of sucks.
I fixed it for you (markdown tables support padding to make them easy to read):
markdown table x y |markdown|table| |--------|-----| |x |y |deleted by creator, who realised their misunderstanding
Markdown tables are terrible though. Try and put a code block in there. Adoc tables are amazing on the other hand, but much more verbose to write.
I’d argue this syntax is difficult to read, especially as it scales
The syntax is only difficult to read in their example.
I fixed their example here: https://programming.dev/comment/12087783
Zigbee or really any Bluetooth alternative.
Bluetooth is a poorly engineered protocol. It jumps around the spectrum while transmitting, which makes it difficult and power intensive for bluetooth receivers to track.
I agree Bluetooth (at least Bluetooth Classic) is not very well designed, but not because of frequency hopping. That improves robustness and I don’t see why it would cost any more power. The hopping pattern is deterministic. Receivers know in advance which frequency to hop to.
I’ll give my usual contribution to RSS feed discourse, which is that, news flash! RSS feeds support video!
It drives me crazy when podcasters are like, “thanks for listening to our audio podcasts. We also have a video feed for our YouTube subscribers.” Just let me have the video in PocketCasts please!
I feel you but i dont think podcasters point to youtube for video feeds because of a supposed limitation of RSS. They do it because of the storage and bandwidth costs of hosting video.
I’d think they’d get it back by not having to share their ad rev with Google. There’s something to be said for the economies of scale Google benefits from but with cloud services that’s not as relevant as it was.
I just wrote a YouTube scraper and exported to RSS and into my podcast client. Using YouTube any other way is masochism in comparison.
PGP or GPG, however you spell it. You can encrypt stuff, protect your email from prying eyes!
Also FOSS in general.
The tooling around it needs to be brought up to snuff. It seems like it hasn’t evolved much in the last 20+ years.
I had a small team make an attempt to use it at work. Our conclusion was that it was too clunky. Email plugins would fool you into thinking it was encrypted when it wasn’t. When it did encrypt, the result wasn’t consistently readable by plugins on the receiving end. The most consistent method was to write a plaintext doc, encrypt it, and attach the encrypted version to the email. Also, key servers are setup by amateurs who maintain them in their spare time, and aren’t very reliable.
One of the more useful things we could do is have developers sign their git commits. GitHub can verify the signature using a similar setup to SSH keys.
It’s also possible to use TLS in a web of trust way, but the tooling around it doesn’t make it easy.
Huge fan of PHP…I mean PGP, oh god auto correct, you scary 😳
This isn’t exactly what you asked, but our URI/URL schema is basically a bunch of missed opportunities, and I wish it was better designed.
Ok so it starts off with the scheme name, which makes sense. http: or ftp: or even tel:
But then it goes into the domain name system, which suffers from the problem that the root, then top level domain, then domain, then progressively smaller subdomains, go right to left. www.example.com requires the system look up the root domain, to see who manages the .com tld, then who owns example.com, then a lookup of the www subdomain. Then, if there needs to be a port number specified, that goes after the domain name, right next to the implied root domain. Then the rest of the URL, by default, goes left to right in decreasing order of significance. It’s just a weird mismatch, and would make a ton more sense if it were all left to right, including the domain name.
Then don’t get me started about how the www subdomain itself no longer makes sense. I get that the system was designed long before HTTP and the WWW took over the internet as basically the default, but if we had known that in advance it would’ve made sense to not try to push www in front of all website domains throughout the 90"s and early 2000’s.
Then don’t get me started about how the www subdomain itself no longer makes sense. I get that the system was designed long before HTTP and the WWW took over the internet as basically the default, but if we had known that in advance it would’ve made sense to not try to push www in front of all website domains throughout the 90"s and early 2000’s.
I have never understood why you can delegate a subdomain but not the root domain, I doubt it was a technical issue because they added support for it recently via
SVCBrecords (But maybe technical concerns were actually fixed in the decades since)Don’t worry, in 5 or 10 years Google will develop an alternative and the rest of FAANG will back it. It will be super technically correct but will include a cryptographic signature that only big tech companies can issue.
This is actually exactly what I asked for, thank you!!
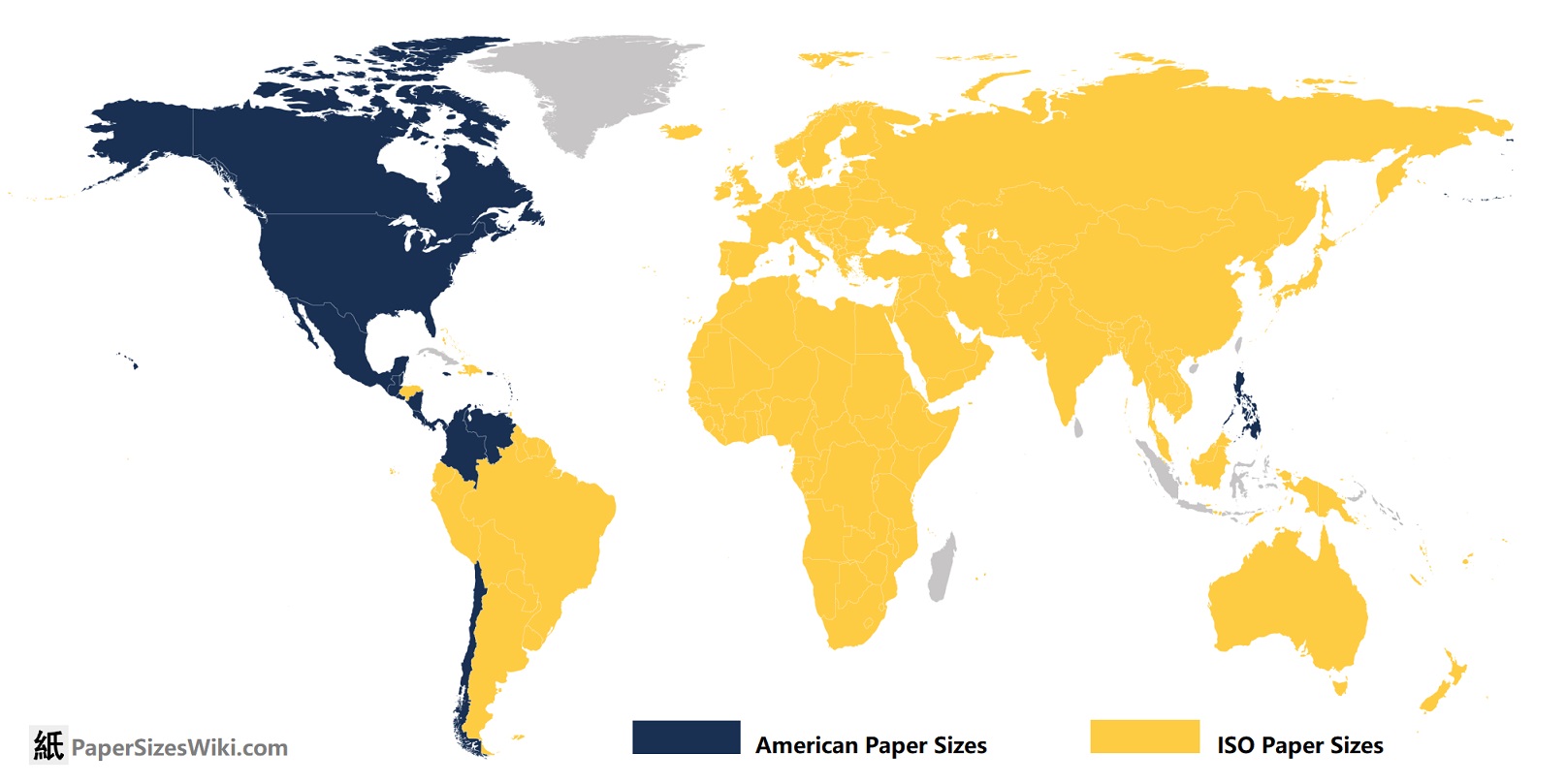
ISO 216 paper sizes work like this: https://www.printed.com/blog/paper-size-guide/
It’s so fucking neat and intuitive! How is it not used more???
sorry to tell you this bud…
Clearly the rest of the world are communists! It’s not us, it’s you! I’m not crying you’re crying! 😭😭😭
It’s also worth noting that switching from ANSI to ISO 216 paper would not be a substantial physical undertaking, as the short-side of even-numbered ISO 216 paper (eg A2, A4, A6, etc) is narrower than for ANSI equivalents. And for the odd-numbered sizes, I’ve seen Tabloid-size printers in America which generously accommodate A3.
For comparison, the standard “Letter” paper size (aka ANSI A) is 8.5 inches by 11 inches. (note: I’m sticking with American units because I hope Americans read this). Whereas the similar A4 paper size is 8.3 inches by 11.7 inches. Unless you have the rare, oddball printer which takes paper long-edge first, this means all domestic and small-business printers could start printing A4 today.
In fact, for businesses with an excess stock of company-labeled #10 envelopes – a common size of envelope, measuring 4.125 inches by 9.5 inches – a sheet of A4 folded into thirds will still (just barely) fit. Although this would require precision folding, that’s no problem for automated letter mailing systems. Note that the common #9 envelope (3.875 inches by 8.875 inches) used for return envelopes will not fit an A4 sheet folded in thirds. It would be advisable to switch entirely to A series paper and C series envelopes at the same time.
Confusingly, North America has an A-series of envelopes, which bear no relation to the ISO 216 paper series. Fortunately, the overlap is only for the less-common A2, A6, and A7.
TL;DR: bring reams of A4 to the USA and we can use it. And Tabloid-size printers often accept A3.
My printer will print and scan any A side paper. But I can’t even buy A paper! Fucking America
Presumably you could just buy that paper size? They’re pretty similar sizes; printers all support both sizes. I’ve never had an issue printing a US Letter sized PDF (which I assume I have done).
Kind of weird that you guys stick to US Letter when switching would be zero effort. I guess to be fair there aren’t really any practical benefits either.
I’ve literally never even seen A paper in America. Probably would have to special order it from another country
Ah fair enough.
I mean I’d love to use it. Of course America is behind the times of civilized nations.
Also, A4 simply has a better ratio than letter. Letter is too wide, making A4 better to hold and it fits more lines per page.
Most preschool kids know what an A4 sheet is. Not sure how it can be used more.
https://cuelang.org/. I deal with a lot of k8s at work, and I’ve grown to hate YAML for complex configuration. The extra guardrails that Cue provides are hugely helpful for large projects.
Oh this! YAML was a terrible choice. And that’s coming from someone who likes Python and prefers white spaces over brackets. YAML never clicked for me.
What you mean you can’t easily tell what this is?
- foo: - - : - bar: baz: [ - - ]
Oh, this looks great!
I’ve been struggling between customize and helm. Neither seem to make k8s easier to work with.I have to try cuelang now. Something sensible without significant whitespace that confuses editors, variables without templating.
I’ll have to see how it holds up with my projectsHmm, what alternative? XML :-)? People hate Grade DSL just for not being xml