

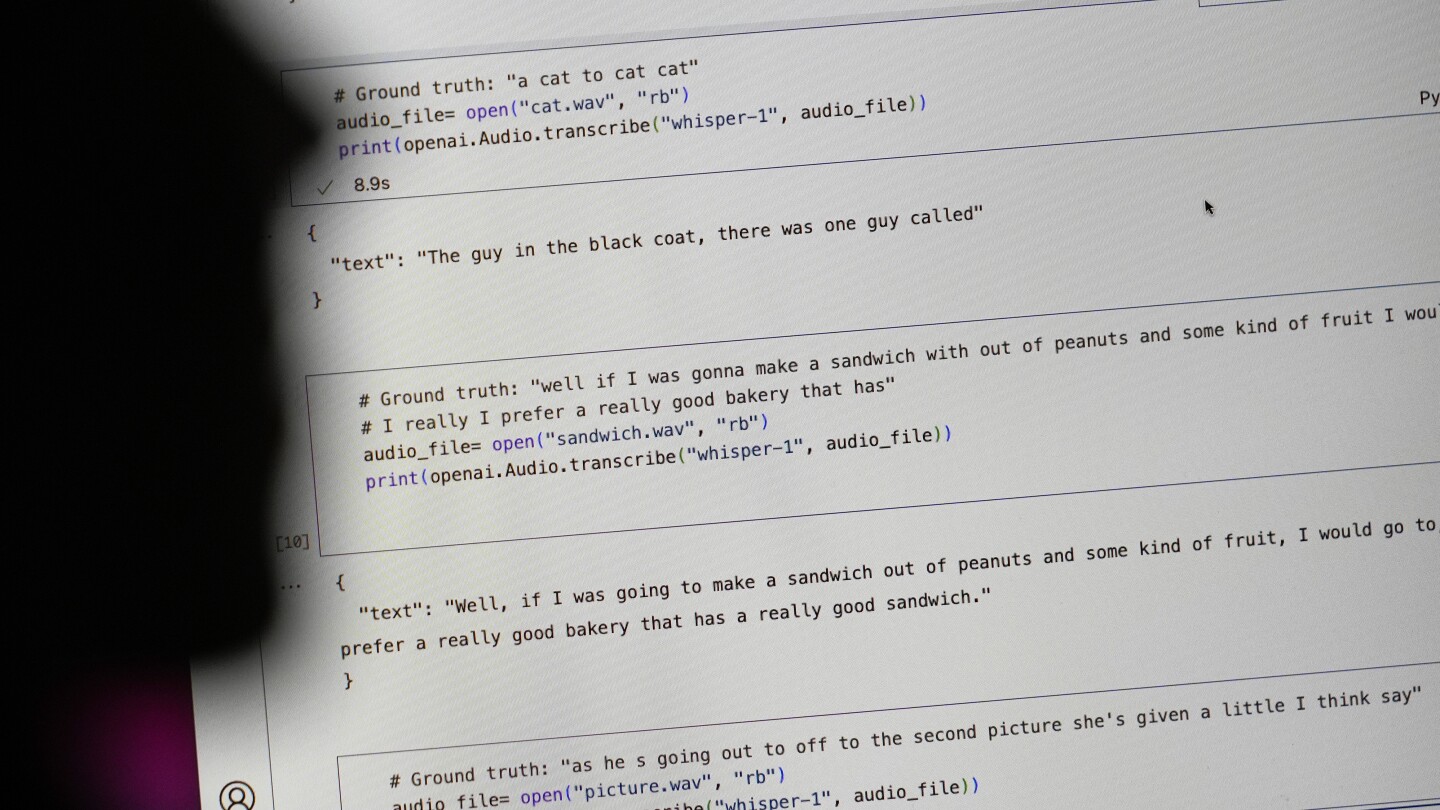
Tech behemoth OpenAI has touted its artificial intelligence-powered transcription tool Whisper as having near “human level robustness and accuracy.”
But Whisper has a major flaw: It is prone to making up chunks of text or even entire sentences, according to interviews with more than a dozen software engineers, developers and academic researchers. Those experts said some of the invented text — known in the industry as hallucinations — can include racial commentary, violent rhetoric and even imagined medical treatments.
Experts said that such fabrications are problematic because Whisper is being used in a slew of industries worldwide to translate and transcribe interviews, generate text in popular consumer technologies and create subtitles for videos.
More concerning, they said, is a rush by medical centers to utilize Whisper-based tools to transcribe patients’ consultations with doctors, despite OpenAI’ s warnings that the tool should not be used in “high-risk domains.”
deleted by creator
Odd that GPT (and of course all the LLMs too) only got better so far…
The architecture changed, there is still progress to be made there. But LLMs will forever be stuck in 2021, all data afterwards is tainted. Not a lot has been added.
In fact, Whisper was developed to transcribe videos for more training data, because they ran out of text data. These bad transcriptions are in newer models.
Shoveling in more data was only the fix when we had paltry amounts of data. Sheer quantity powered over the hump and proved that neural networks… work. What’s proven unreasonably effective since then is deeper structure with more training. Especially adversarial training, which specifically teaches the model to spot generated content, versus real training data.
Big-data companies are still pushing big data because it reduces competition. They are the only ones who can offer that kind of scale, and they’re trying to trick every business on Earth into using AI somewhere, so it is in their interest to continue this specific trend.