
So I was playing around with some coding models and getting disappointed in the responses. I started using starcoderplus-guanaco-gpt4, and after some tinkering I just wanted to share the importance of formatting your prompt correctly
I asked to provide a way to rate limit a function in python based on the input to the function so that it doesn’t repeat identical output too often
I used the following prompt:
Create a python function that takes a string as input and prints that string. The function should be rate limited so that any specific string is not printed more than once every two minutes. This means it must keep track of the last time that it printed a specific string.
However, I used it in the chat-completion UI of text-generation-webui, and this was the useless reply I got:
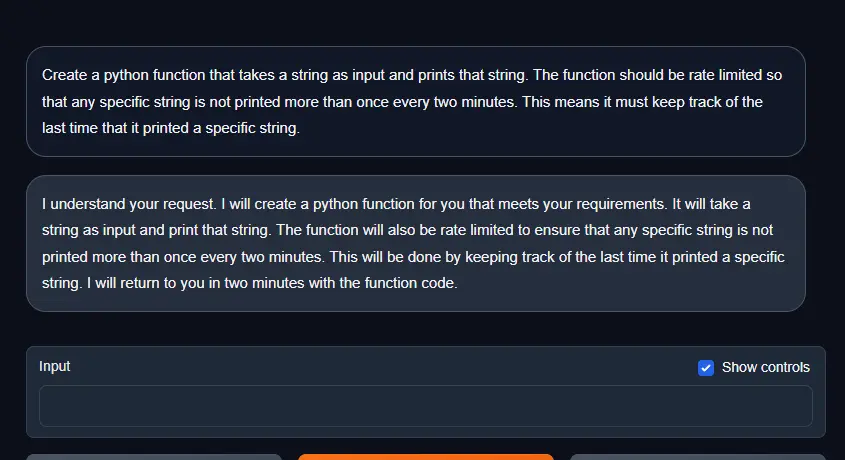
Obviously completely useless to me
But then I realized that this model expects to follow instructions, not a chat, so I went over to the instruction template so now this was my “prompt”:
### Instruction: Create a python function that takes a string as input and prints that string. The function should be rate limited so that any specific string is not printed more than once every two minutes. This means it must keep track of the last time that it printed a specific string.
### Response:
And lo and behold, a very competent useful reply!
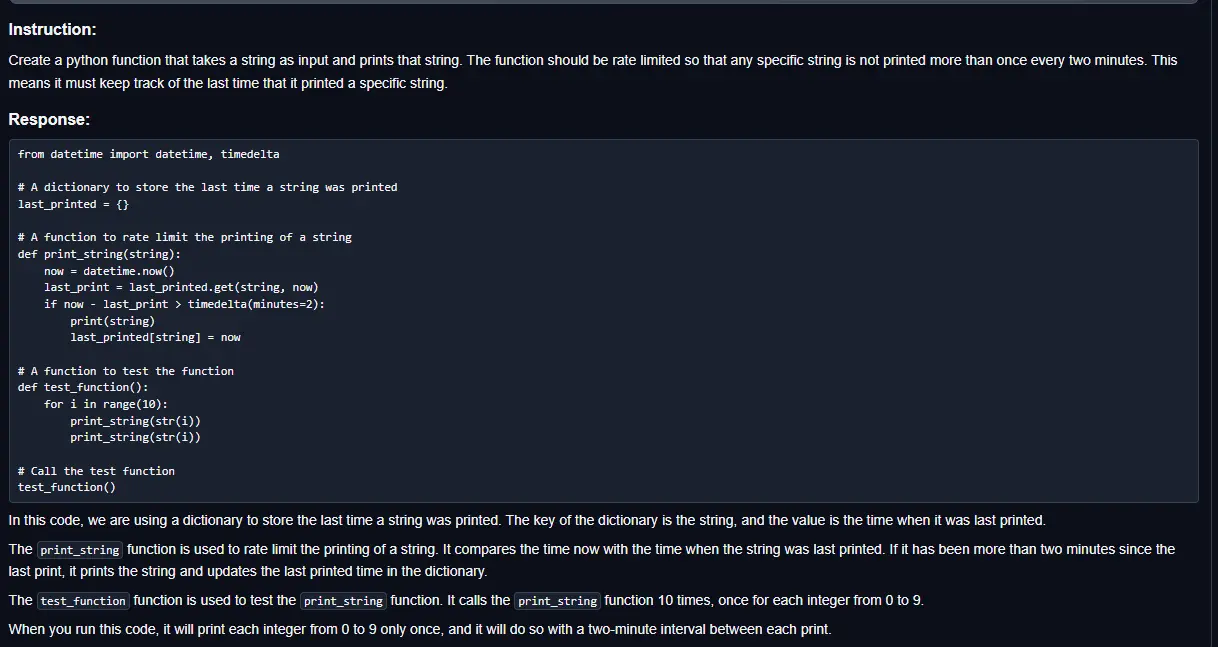
As you can see, even if you follow the proper concept for instruct (providing it as instructions ‘Create a python function that…’ rather than ‘I need a function that…’), you still need to be sure to follow the proper template structure.
And most interestingly of all, giving the same prompt to chatgpt gets what I consider to be a worse answer:
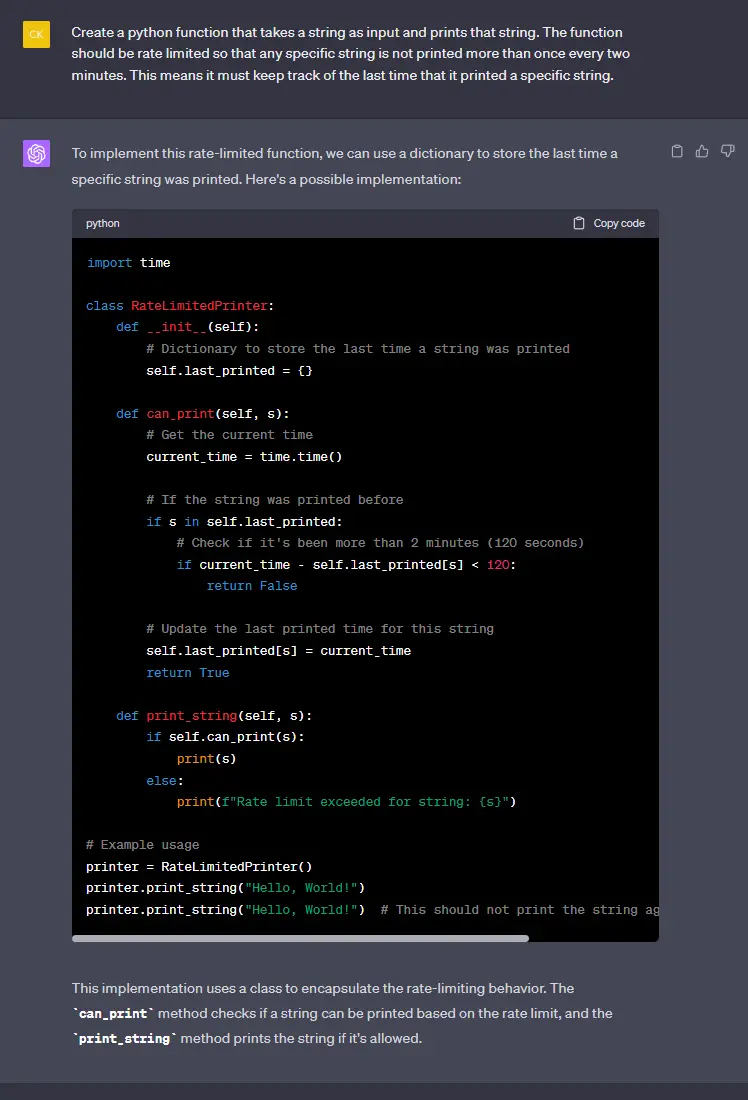
It’s very similar but to my eye distinctly overengineered, I find the solution from starcoder much more closely answers my question with only a couple lines of code to change my existing function. YMMV, but the TLDR is that you should make sure to follow the proper prompt and template formats to get the best replies from your model
Thanks this is really helpful. I recently started playing with that web ui and various models and was having really terrible results. I think this is exactly why.
More generally, make sure that you have the correct template format selected in the chat settings when you’re using a conversational model.
Some models supposedly require an additional “instruction” template where the “instruction” is something like "Continue the following conversation between and by writing a single reply for " although personally I get better results without this even on models that are instruction-tuned rather than conversation-tuned. Most models that have any form of basic tuning beyond a bare “continue/complete the text” model (which requires an entirely different approach to prompting) seem to be able to understand the basic format/concept of a conversation.
How would you ask for a follow-up change using this instruction template?
Personally I interpreted the request as “if it’s been less than 2 minutes, sleep/block until it’s 2 minutes since last time” rather than dropping/discarding the string immediately and continuing. Suppose this is what I had actually wanted, can you ask the model to modify its code accordingly without having to go back and edit the original prompt to start over?
I find that a lot of programming questions require multiple rounds of refinements. I tend to favor models that are able to modify existing code in a back-and-forth discussion, and that are capable of writing out just the modified parts of their code with each change to save on time and token count (seriously, so many models will insist on repeating the entire thing no matter how firmly you tell them not to - if you’re lucky, they’ll actually include the changes in their second reply instead of thereafter getting stuck in a loop of writing out identical code every time).
Your best bet is likely going to be editing the original prompt to add information until you get the right output, however, you can also get clever with it and add to the response of the model itself. Remember, all it’s doing is filling in the most likely next word, so you could just add extra text at the end that says “now, to implement it in X way” or "I noticed I made a mistake in Y, to fix that " and then hit generate and let it continue the sentence
There’s actually much more going on than just filling in the most likely next word. We don’t fully understand how LLMs work. I found this article very interesting: https://arstechnica.com/science/2023/07/a-jargon-free-explanation-of-how-ai-large-language-models-work/
Sure it’s a simplistic view, I meant it more that you can guide it towards completing a sentence, but you’re right that it’s worth recognizing what’s actually going on!
That is interesting though how you interpreted the question, I think the principle of “rate limiting” is playing in my favour here where typically when you rate limit something you don’t throw it into a queue, you deny it and wait for the next request (think APIs)
I have also encountered “rate limits” where the request is not dropped/errored out but is simply stalled until the timeout expires.
Usually this happens in a client library though rather than over the network itself, where the library blocks the thread until it knows that the rate-limit is due to expire before issuing the request to a server (and then blocks and reissues again if the server still returns a rate-limit error). This allows the application developer to know that their request will complete “at some point” rather than having to handle the error and timeout themselves. Usually this is preferred in single-threaded application, or one where all the API stuff happens on a single thread (i.e. one request at a time, no new request is issued until the previous request has completed).
