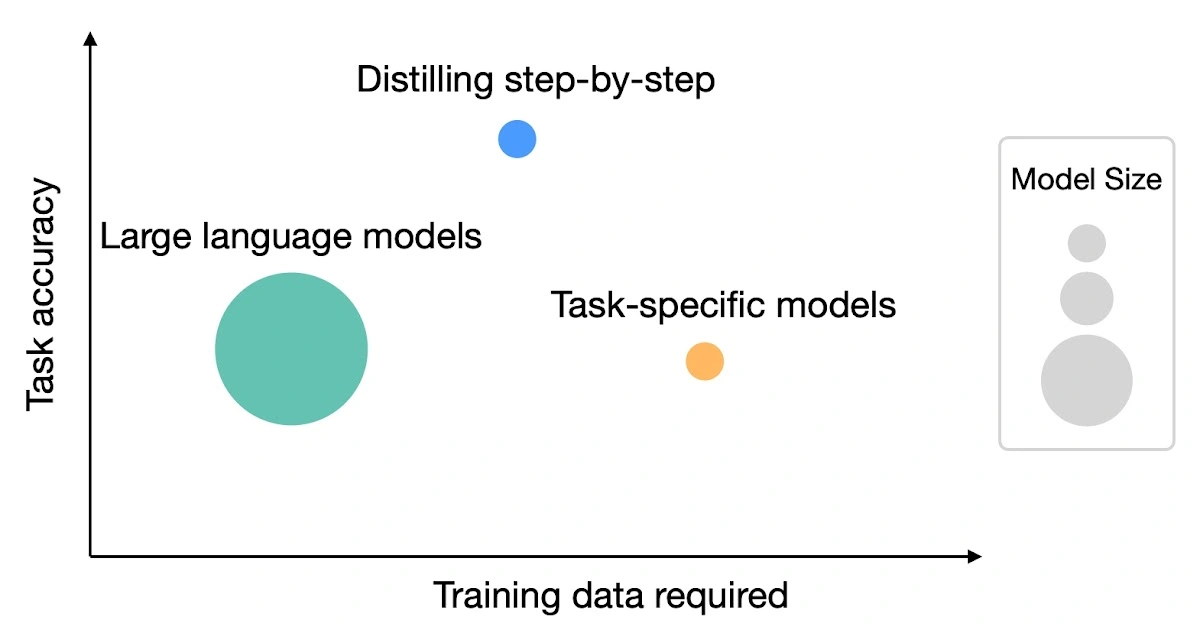
Zetaphor@zemmy.cc to LocalLLaMAEnglish · 1 年前Distilling step-by-step: Outperforming larger language models with less training data and smaller model sizesblog.research.googleexternal-linkmessage-square3fedilinkarrow-up128arrow-down10cross-posted to: [email protected][email protected][email protected]
arrow-up128arrow-down1external-linkDistilling step-by-step: Outperforming larger language models with less training data and smaller model sizesblog.research.googleZetaphor@zemmy.cc to LocalLLaMAEnglish · 1 年前message-square3fedilinkcross-posted to: [email protected][email protected][email protected]
minus-squareZetaphor@zemmy.ccOPlinkfedilinkEnglisharrow-up2·1 年前The code is available here: https://github.com/google-research/distilling-step-by-step
minus-squarenoneabove1182MlinkfedilinkEnglisharrow-up1·1 年前Somehow this is even more confusing because that code hasn’t been touched in 3 months, maybe just took them that long to validate? Will have to read through it, thanks!


The code is available here:
https://github.com/google-research/distilling-step-by-step
Somehow this is even more confusing because that code hasn’t been touched in 3 months, maybe just took them that long to validate? Will have to read through it, thanks!