

I found this funny.
The context is as explained by @[email protected]
the issue is that you can’t return from inside a closure, since the closure might be called later/elsewhere
and this post was the asnwer to the question by @[email protected]
you got me curious what the record for the longest
?operator chain on crates.io is
Original post: https://fosstodon.org/users/antonok/statuses/111134824451525448
You must log in or register to comment.
While funny, this also highlights part of why I like rust’s error handling story so much: You can really just read the happy path and understand what’s going on. The error handling takes up minimal space, yet with one glance you can see that errors are all handled (bubbled up in this case). The usual caveats still apply, of course ;)
I’m writing my Rust wrong… I have match statements everywhere to the degree that it’s cluttering up everything.
If all you do in the
Err(e) => ...match arm is returning the error, then you absolutely should use the?operator instead.If the match arm also converts the error type into another error type, implement the
Fromtrait for the conversion, then you can use?as well.If you want to add more information to the error, you can use
.map_err(...)?. Or, if you’re using theanyhowcrate,.with_context(...)?.You can also do
map_err, which is a bit cleaner while keeping the mapping obvious. If you really need to do some logic on error, extracting that to the calling function is often better.
If the matches are causing too much nesting/rightward drift, then that could be an indicator that you’re doing something wrong.
If it’s the opposite, then you’re probably doing something right, except maybe the code needs some refactoring if there is too much clutter.
If there isn’t much difference, then it’s a matter of style. I for example sometimes prefer to match on
bools in some contexts because it makes things look clearer to me, despite it being not the recommended style. I’m also a proud occasional user ofbool::then()andbool::then_some()😉Also, if you find yourself often wishing some API was available for types like
bool,Option, andResult, then you don’t have to wish for long. Just write some utility extension traits yourself! I for example have methods likebool::err_if(),bool::err_if_not(),Option::none_or_else(), and some more tailored to my needs methods, all available via extension traits.Macros can also be very useful, although some people go for them too early. So if everything else fails to declutter your code, try writing a macro or two.
And it’s worth remembering, there is no general rule, other than if the code is understandable for you and works, then you’re probably okay irregardless of style. It’s all sugar after all, unless you’re really doing some glaringly wrong stuff.
Most likely you can get by with adjusting the return type and using a ? or maping to a type that you can use the ? on.
People who know monad: ???
People who don’t know monad: ???
Is everyone genuinely liking this!
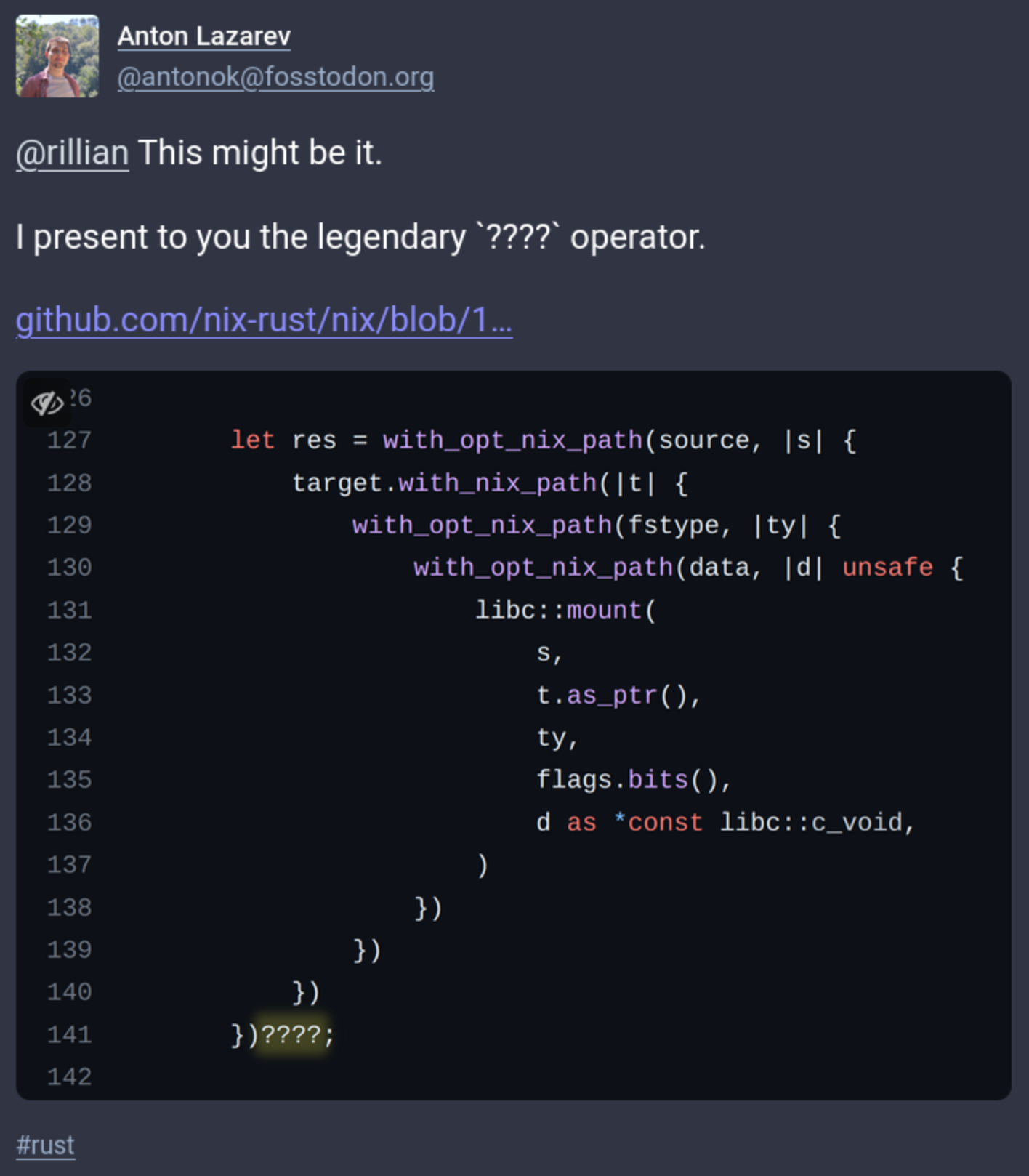
This is, IMHO, not a good style.
Isn’t something like this much clearer?
// Add `as_cstr()` to `NixPath` trait first let some_or_null_cstr = |v| v.map(NixPath::as_cstr) .unwrap_or(Ok(std::ptr::null())); // `Option::or_null_cstr()` for `OptionᐸTᐳ` // where `T: NixPath` would make this even better let source_cstr = some_or_null_cstr(&source)?; let target_cstr = target.as_cstr()?; let fs_type_cstr = some_or_null_cstr(&fs_type)?; let data_cstr = some_or_null_cstr(&data)?; let res = unsafe { .. };Edit: using alternative chars to circumvent broken Lemmy sanitization.
I think the issue with this is that the code (https://docs.rs/nix/0.27.1/src/nix/lib.rs.html#297) allocates a fixed-size buffer on the stack in order to add a terminating zero to the end of the path copied into it. So it just gives you a reference into that buffer, which can’t outlive the function call.
They do also have a
with_nix_path_allocatingfunction (https://docs.rs/nix/0.27.1/src/nix/lib.rs.html#332) that just gives you aCStringthat owns its buffer on the heap, so there must be some reason why they went this design. Maybe premature optimization? Maybe it actually makes a difference? 🤔They could have just returned the buffer via some wrapper that owns it and has the
as_cstrfunction on it, but that would have resulted in a copy, so I’m not sure if it would have still achieved what they are trying to achieve here. I wonder if they ran some benchmarks on all this stuff, or they’re just writing what they think will be fast.so there must be some reason why they went this design.
Some applications have a hard zero-alloc requirement.
But that’s not the case here, seeing as they have
if self.len() >= MAX_STACK_ALLOCATION { return with_nix_path_allocating(self, f); }in the code of with_nix_path. And I think they still could’ve made it return the value instead of calling the passed in function, by using something like
enum NixPathValue { Short(MaybeUninitᐸ[u8; 1024]>, usize), Long(CString) } impl NixPathValue { fn as_c_str(&self) -> &CStr { // ... impl NixPath for [u8] { fn to_nix_path(&self) -> ResultᐸNixPathValue> { // return Short(buf, self.len()) for short paths, and perform all checks here, // so that NixPathValue.as_c_str can then use CStr::from_bytes_with_nul_uncheckedBut I don’t know what performance implications that would have, and whether the difference would matter at all. Would there be an unnecessary copy? Would the compiler optimize it out? etc.
Also, from a maintainability standpoint, the context through which the library authors need to manually ensure all the unsafe code is used correctly would be slightly larger.
As a user of a library, I would still prefer all that over the nesting.
I never though about chaining
?! This is hilarious and I need to use it somewhere now.yeah i didnt realize you could do that either lmao.
It make total sense, I just never ran into a
Result(Result(Result(T, E), E), E)situationEdit: Lemmy is so scared of cross site scripting, they simply remove all less than and greater than signs, lmao
And it replaces ampersands.
there was a comment about adding an
?!operator that would resolve any number of?operators but I can’t find it.‽Interrobang gang rise up!
I can’t remember ever needing more than two question marks (
??), and even that is very rare in my experience.
I feel like a ???-operator would help many languages
Scala has one, which throws a NotImplemented error
Runtime or compile-time? If run-time, that sounds like a fun way to implement something like
panic().runtime, the point is so that you can see if the types align and then come back and fill in the function bodies later
Awesome, reminds me of
-->operator: https://stackoverflow.com/questions/1642028/what-is-the-operator-in-c-cOh, like the LISP “close all”!
deleted by creator
deleted by creator
deleted by creator





{kind=link}