camel-cdr
- 16 Posts
- 3 Comments
Joined 1 year ago
Cake day: June 13th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.





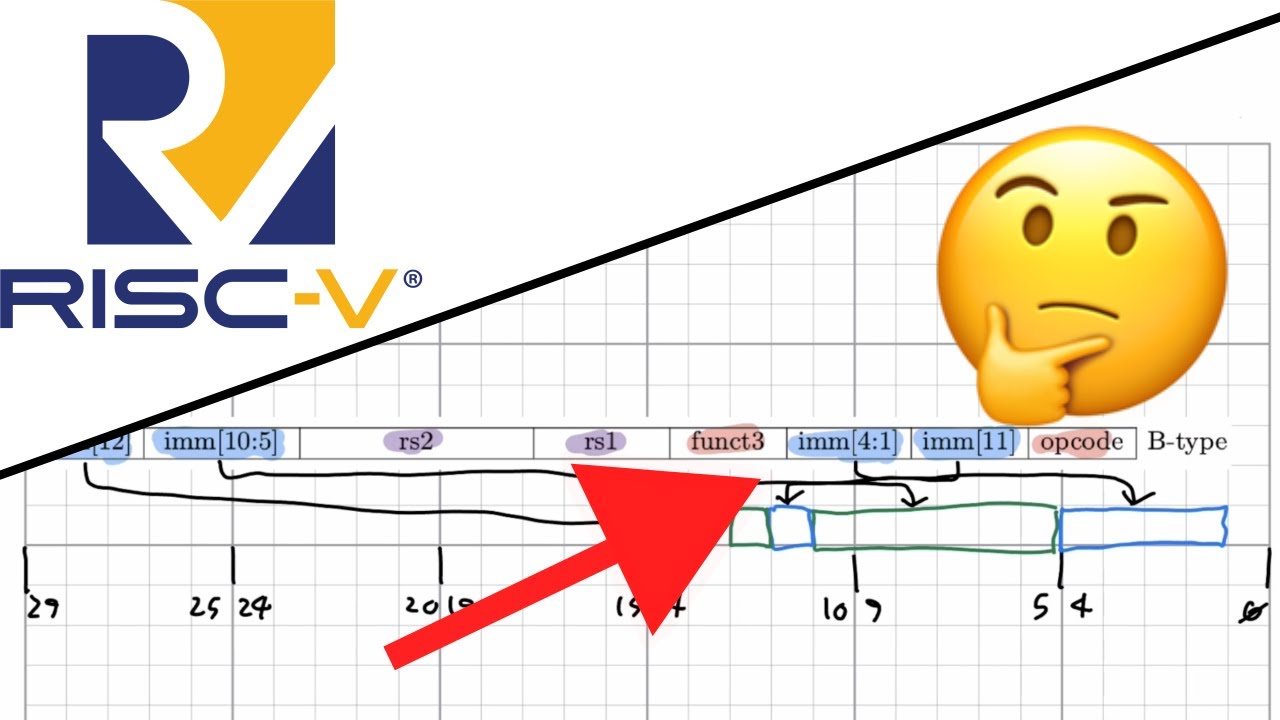







 3·1 year ago
3·1 year agoThe critical section makes sure that only ever a single thread can execute the section at a time. So when a thread what’s to execute the section, it first needs to make sure no other thread is executing it and potentially wait for the other threads to finish executing the section.
Reductions however don’t induce this synchronization overhead, instead each thread executes with an independent
parentvalue, and after the loop is done, the reduction is applied to merge allparentvalues. The following, is essentially what the#pragma omp parallel for reduction(min : parent)is equivalent to:unsigned int parents[8] = {v, v, v, v, v, v, v, v}; #pragma omp parallel for num_threads(8) for(unsigned int j = 0; j < G.Out[v]._map.bucket_count(); j++) { for(auto ite = G.Out[v]._map.begin(j); ite != G.Out[v]._map.end(j); ite++) { unsigned int w = ite->first; if(v > w) parents[omp_get_thread_num()] = min(parents[omp_get_thread_num()],w); } } unsigned int parent = v; for (unsigned int i = 0; i < 8; ++i) { parent = min(parent, parents[i]); }


I mainly use metal-archives and bandcamp

I’m not a local programming.dev resident, but I’d be interested in a code golf community.
It could be really fun to host/participate in challenge threads, and posts about some fun golfs.