I highly doubt that they would be able to use private user data for training. Using data available on the internet is a bit legally grey, but using data that is not publicly available would surely be illegal. When the document is “read” by the LLM it is no longer training, so it won’t store the data and be able to regurgitate it.*
* that is, if they have designed this in an ethical and legal way 🙃
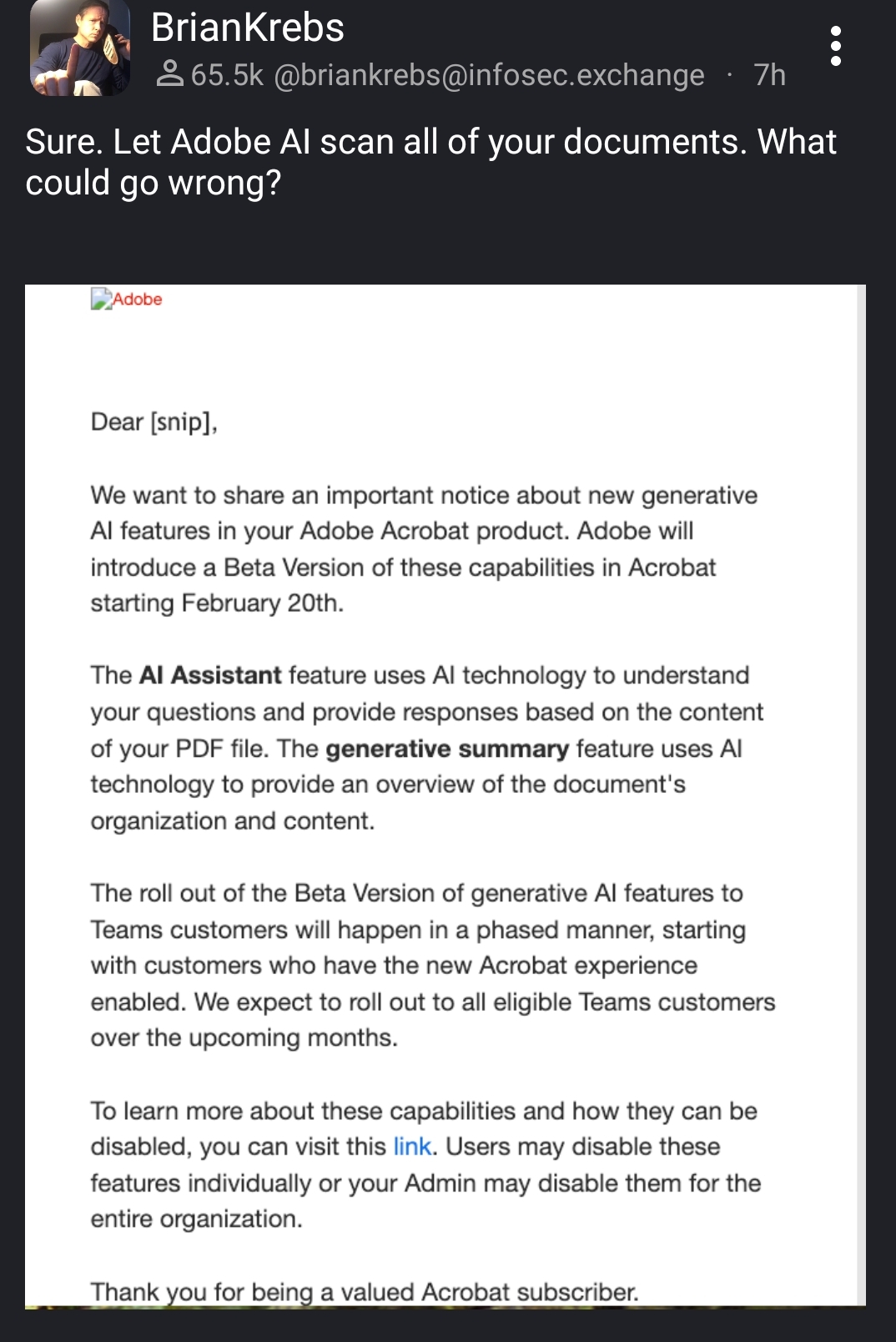
They will use every scrap of data you haven’t explicitly told them not to use, and they will make it so that the method to disable these ‘features’ is little known, difficult to understand/access, and automatically re-enabled every release cycle.
When they are sued, they will point to announcements like this and the one or two paragraphs in their huge EULA to discourage, dismiss, and slow down lawsuits.
I suspect that they will explicitly advertise that they won’t be using any data for training. Just like Microsoft Copilot enterprise (or whatever it’s called) and Bing chat enterprise.
Companies absolutely know the risk with these systems and will never allow or buy a system that scans and saves their data.
I had a second part of my comment that I left off because I felt like I was hitting the point too hard, but…
I have firsthand knowledge of an organization that’s a GCC tenant. That’s the government cloud, and in mid-2022 Microsoft rolled out a product called Microsoft Viva without first consulting with platform admins. They just pushed it out into M365, activated and enabled. A personalized automated email was sent out to every person within the org, from Microsoft.com, with snippets of emails deemed to be follow up items by “Cortana” - which platform admins had disabled on every computer within the org. It was pretty clear that Microsoft had exfiltrated government data, analyzed it, and then sent emails to users regarding their analysis.
Platform admins did find a way to disable it within a few days, and leadership sent out an email characterizing the episode as a misconfigured, early release feature to assuage concerns. They promised to get to the bottom of it with Microsoft, and nothing was ever heard about it again.
Then earlier this year - multiple pushes of consumer apps and features which are not released on the GCC roadmap. Automatic install of New Teams, which - thankfully, displays a message that the user isn’t licensed for it, but that creates IT tickets because it auto-launches and disables classic teams from auto-launching. Lots of user confusion there. New Outlook, which didn’t support data classification, multiple mailboxes, and many of the features that make Outlook useful. It’s been a huge boondoggle as users have enabled new Outlook, and then don’t know how to switch back to a working version of Outlook. Recently everyone’s PowerBI began failing to launch, because Microsoft rolled out a OneDrive/SharePoint integration without testing it. Same with HP Print manager.
My point in all that is not just to have a laundry list of Microsoft failures. I have a list for Adobe, too, but it’s to establish that updates are not vetted, and often just pushed into the wrong update channels.
When pressed, it’s always a ‘configuration error’ or an accidental early release. A bug or what-have-you.
The line from annoying to dangerous is going to be quickly crossed once these companies start training AI on the harvested PII and government data they’ve procured through the sloppy deployment practices they’re already engaged in.
I guarantee you that rogue hackers and nation states alike are working on fuzzing every AI dataset they can, to see if it picked up anything juicy. Once Adobe gets their hands on everyone’s scanned health record, classified documents, and credit card application, we’re going to see an endless stream of ‘whoopsies.’
A corporation that charges a monthly subscription for products it could sell outright. Offers it to students at a time when they are most likely to develop habits in it, uses a proprietary storage format that only works well with their products.
Once you get a customer addicted, you’ve got them for life.

{kind=link}
I highly doubt that they would be able to use private user data for training. Using data available on the internet is a bit legally grey, but using data that is not publicly available would surely be illegal. When the document is “read” by the LLM it is no longer training, so it won’t store the data and be able to regurgitate it.*
* that is, if they have designed this in an ethical and legal way 🙃
They will use every scrap of data you haven’t explicitly told them not to use, and they will make it so that the method to disable these ‘features’ is little known, difficult to understand/access, and automatically re-enabled every release cycle. When they are sued, they will point to announcements like this and the one or two paragraphs in their huge EULA to discourage, dismiss, and slow down lawsuits.
I suspect that they will explicitly advertise that they won’t be using any data for training. Just like Microsoft Copilot enterprise (or whatever it’s called) and Bing chat enterprise.
Companies absolutely know the risk with these systems and will never allow or buy a system that scans and saves their data.
I had a second part of my comment that I left off because I felt like I was hitting the point too hard, but…
I have firsthand knowledge of an organization that’s a GCC tenant. That’s the government cloud, and in mid-2022 Microsoft rolled out a product called Microsoft Viva without first consulting with platform admins. They just pushed it out into M365, activated and enabled. A personalized automated email was sent out to every person within the org, from Microsoft.com, with snippets of emails deemed to be follow up items by “Cortana” - which platform admins had disabled on every computer within the org. It was pretty clear that Microsoft had exfiltrated government data, analyzed it, and then sent emails to users regarding their analysis.
Platform admins did find a way to disable it within a few days, and leadership sent out an email characterizing the episode as a misconfigured, early release feature to assuage concerns. They promised to get to the bottom of it with Microsoft, and nothing was ever heard about it again.
Then earlier this year - multiple pushes of consumer apps and features which are not released on the GCC roadmap. Automatic install of New Teams, which - thankfully, displays a message that the user isn’t licensed for it, but that creates IT tickets because it auto-launches and disables classic teams from auto-launching. Lots of user confusion there. New Outlook, which didn’t support data classification, multiple mailboxes, and many of the features that make Outlook useful. It’s been a huge boondoggle as users have enabled new Outlook, and then don’t know how to switch back to a working version of Outlook. Recently everyone’s PowerBI began failing to launch, because Microsoft rolled out a OneDrive/SharePoint integration without testing it. Same with HP Print manager.
My point in all that is not just to have a laundry list of Microsoft failures. I have a list for Adobe, too, but it’s to establish that updates are not vetted, and often just pushed into the wrong update channels.
When pressed, it’s always a ‘configuration error’ or an accidental early release. A bug or what-have-you.
The line from annoying to dangerous is going to be quickly crossed once these companies start training AI on the harvested PII and government data they’ve procured through the sloppy deployment practices they’re already engaged in.
I guarantee you that rogue hackers and nation states alike are working on fuzzing every AI dataset they can, to see if it picked up anything juicy. Once Adobe gets their hands on everyone’s scanned health record, classified documents, and credit card application, we’re going to see an endless stream of ‘whoopsies.’
All the ones I’ve seen that are aimed at companies have explicit terms that protect your data and don’t allow it to be shared anywhere.
But that’s just like, a suggestion, man.
And it’s kind of predicated on their admins being highly proactive about data protection, because the vendors certainly aren’t.
Thus is adobe we’re talking about…
A corporation that charges a monthly subscription for products it could sell outright. Offers it to students at a time when they are most likely to develop habits in it, uses a proprietary storage format that only works well with their products.
Once you get a customer addicted, you’ve got them for life.