


“LLMs such as they are, will become a commodity; price wars will keep revenue low. Given the cost of chips, profits will be elusive,” Marcus predicts. “When everyone realizes this, the financial bubble may burst quickly.”
Please let this happen
Market crash and third world war. What a time to be alive!
I wish just once we could have some kind of tech innovation without a bunch of douchebag techbros thinking it’s going to solve all the world’s problems with no side effects while they get super rich off it.
… bunch of douchebag techbros thinking it’s going to solve all the world’s problems with no side effects…
one doesn’t imagine any of them even remotely thinks a technological panacaea is feasible.
… while they get super rich off it.
because they’re only focusing on this.
Oh they definitely exist. At a high level the bullshit is driven by malicious greed, but there are also people who are naive and ignorant and hopeful enough to hear that drivel and truly believe in it.
Like when Microsoft shoves GPT4 into notepad.exe. Obviously a terrible terrible product from a UX/CX perspective. But also, extremely expensive for Microsoft right? They don’t gain anything by stuffing their products with useless annoying features that eat expensive cloud compute like a kid eats candy. That only happens because their management people truly believe, honest to god, that this is a sound business strategy, which would only be the case if they are completely misunderstanding what GPT4 is and could be and actually think that future improvements would be so great that there is a path to mass monetization somehow.
That’s not what’s happening here. Microsoft management are well aware that AI isn’t making them any money, but the company made a multi billion dollar bet on the idea that it would, and now they have to convince shareholders that they didn’t epicly fuck up. Shoving AI into stuff like notepad is basically about artificially inflating “consumer uptake” numbers that they can then show to credulous investors to suggest that any day now this whole thing is going to explode into an absolute tidal wave of growth, so you’d better buy more stock right now, better not miss out.
Yeah my management was all gungho about exploiting AI to do all sorts of stuff.
Like read. Not generative AI crap, but read. They came to us and said quite literally: “how can we use something like ChatGPT and make it read.”
I don’t know who or how they convinced them to use something that wasn’t generative AI, but it did convince me that managers think someone being convincing and confident is correct all the time.
Being convincing and confident without actually knowing is how 9/10s of them make it to the C suite.
That’s probably why they don’t worry about confidently incorrect AI.
Salesmanship is the essence of management at those levels.
Which brings us back around to the original subject of this thread - tech bros - in my own experienced in Tech recently and back in the 90s boom, this generation of founders and “influencers” aren’t techies, they’re people from areas heavy on salesmanship, not actually on creating complex things that objectivelly work.
The complete total dominance of sales types in both domains id why LLMs are being pushed the way they are as if they’re some kind of emerging-AGI and lots of corporates believe it and are trying to hammer those square pegs into round holes even though the most basic of technical analises would tell them that it doesn’t work like that.
Ultimately since the current societal structures we have massively benefit that kind or personality, we’re going to keep on having these kinds of barely-useful-stuff-insanely-hyped-up cycles wasting tons of resources because salesmanship is hardly a synonym for efficiency or wisdom.
Yeah yours is a more thorough and less flippant description of what I meant.
We used to make fun of all the corporate word salad that the Managment would use at my last “real” job. But it really was weird salad all the way down [up].
No no, I disagree I think that shoving AI into all these apps is a solid plan on their behalf. People are going to stop recall and shut it off. So instead they put AI components into every app, It now has the right to overview everything you’re doing and every app collects data on you sending it home to update their personalized models for you so they can better sell you products.
True, they just sell it to their investors as a panacea
Some are just opportunists, but there are certainly true believers — either in specific technologies, or pedal-to-the-metal growth as the only rational solution to the world’s problems.
Andreessen is pretty open about it: https://a16z.com/the-techno-optimist-manifesto/
I think Andreessen is lying and the “techno optimist manifesto” is a ruse for PR.
a16z has been involved in various crypto pump and dumps. They are smart enough to know that something like “play to earn” is not sustainable and always devolves into a pyramid scheme. Doesn’t stop them from getting in early and dumping worthless tokens on the marks.
The manifesto honestly reads like it was written by a teenager. The style, the tone, the excessive quotes from economists. This is pretty typical stuff for American oligarch polemics, no?
Of course most don’t actually even believe it, that’s just the pitch to get that VC juice. It’s basically fraud all the way down.
Soooo… Without capitalism?
Pretty much.
No shit. This was obvious from day one. This was never AGI, and was never going to be AGI.
Institutional investors saw an opportunity to make a shit ton of money and pumped it up as if it was world changing. They’ll dump it like they always do, it will crash, and they’ll make billions in the process with absolutely no negative repercussions.
Then what is this I’m feeling if it’s not AGI? 🤔
Maybe GERD?
Turns out AI isn’t real and has no fidelity.
Machine learning could be the basis of AI but is anyone even working on that when all the money is in LLMs?
I’m not an expert, but the whole basis of LLM not actually understanding words, just the likelihood of what word comes next basically seems like it’s not going to help progress it to the next level… Like to be an artificial general intelligence shouldn’t it know what words are?
I feel like this path is taking a brick and trying to fit it into a keyhole…
learning is the basis of all known intelligence. LLMs have learned something very specific, AGI would need to be built by generalising the core functionality of learning not as an outgrowth of fully formed LLMs.
and yes the current approach is very much using a brick to open a lock and that’s why it’s … ahem … hit a brick wall.
Yeah, 20 something years ago when I was trying to learn PHP of all things, I really wanted to make a chat bot that could learn what words are… I barely got anywhere but I was trying to program the understanding of sentence structure and feeding it a dictionary of words… My goal was to have it output something on its own …
I see these things become less resource intensive and hopefully running not on some random server…
I found the files… It was closer to 15 years ago…
Trying to invent artificial intelligence to learn php is quite funny lol
Also a bit sadistic to be honest. Bringing a new form of life into the world only to subject it to PHP.
I’m amazed I still have the files… But yeah this was before all this shit was big… If I had a better drive I would have ended up more evil than zuck … my plan was to collect data on everyone who used the thing and be able to build profiles on everyone based on what information you gave the chat … And that’s all I can really remember… But it’s probably for the best…
Right, so AIs don’t really know what words are. All they see are tokens. The tokens could be words and letters, but they could also be image/video features, audio waveforms, or anything else.
deleted by creator
shouldn’t it know what words are?
Not necessarily, but it should be smart enough to associate symbols with some form of meaning. It doesn’t do that, it juts associates symbols with related symbols, so if there’s nothing similar that already exists, it’s not going to be able to come back with anything sensible.
I think being able to create new content with partial sample data is necessary to really be considered general AI. That’s what humans do, and we don’t necessarily need the words to describe it.
largely based on the notion that LLMs will, with continued scaling, become artificial general intelligence
Who said that LLMs were going to become AGI? LLMs as part of an AGI system makes sense but not LLMs alone becoming AGI. Only articles and blog posts from people who didn’t understand the technology were making those claims. Which helped feed the hype.
I 100% agree that we’re going to see an AI market correction. It’s going to take a lot of hard human work to achieve the real value of LLMs. The hype is distracting from the real valuable and interesting work.
OpenAI published a paper about GPT titled “Sparks of AGI”.
I don’t think they really believe it but it’s good to bring in VC money
That is a very VC baiting title. But it’s doesn’t appear from the abstract that they’re claiming that LLMs will develop to the complexity of AGI.
You assume most stock investors read beyond the headline, you assume wrong.
Journalists have no clue what AI even is. Nearly every article about AI is written by somebody who couldn’t tell you the difference between an LLM and an AGI, and should be dismissed as spam.
The call is coming from inside. Google CEO claims it will be like alien intelligence so we should just trust it to make political decisions for us bro: https://www.computing.co.uk/news/2024/ai/former-google-ceo-eric-schmidt-urges-ai-acceleration-dismisses-climate
Do you have a non paywalled link? And is that quote in relation to LLMs specifically or AI generally?
I read a lot I guess, and I didn’t understand why they think like this. From what I see, are constant improvements in MANY areas! Language models are getting faster and more efficient. Code is getting better across the board as people use it to improve their own, contributing to the whole of code improvements and project participation and development. I feel like we really are at the beginning of a lot of better things and it’s iterative as it progresses. I feel hopeful
It’s so funny how all this is only a problem within a capitalist frame of reference.
What they call “AI” is only “intelligent” within a capitalist frame of reference, too.
I don’t understand why you’re being downvoted. Current “AI” based on LLM’s have no capacity for understanding of the knowledge they contain (hence all the “hallucinations”), and thus possess no meaningful intelligence. To call it intelligent is purely marketing.

Thank fuck. Can we have cheaper graphics cards again please?
I’m sure a RTX 4090 is very impressive, but it’s not £1800 impressive.
Just wait for the 5090 prices…
I just don’t get whey they’re so desperate to cripple the low end cards.
Like I’m sure the low RAM and speed is fine at 1080p, but my brother in Christ it is 2024. 4K displays have been standard for a decade. I’m not sure when PC gamers went from “behold thine might from thou potato boxes” to “I guess I’ll play at 1080p with upscaling if I can have a nice reflection”.
4k displays are not at all standard and certainly not for a decade. 1440p is. And it hasn’t been that long since the market share of 1440p overtook that of 1080p according to the Steam Hardware survey IIRC.
Maybe not monitors, but certainly they are standard for TVs (which are now just monitors with Android TV and a tuner built in).
That doesn’t really matter if people on PC don’t game on it, does it?
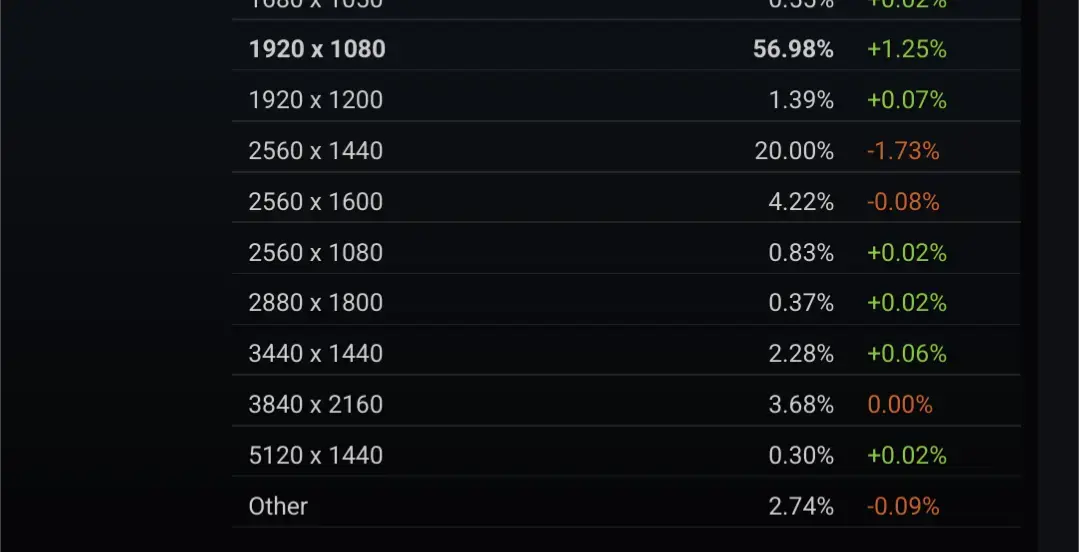
These are the primary display resolutions from the Steam Hardware Survey.
I do wonder how much higher that would be if GPUs targeting 4K were £299 rather than £999.
Although some of it is down to monitors being on desks right in front of you and 4K not really being needed. It would also be interesting to for Valve to weight the results by hours spent gaming that month (and amount they actually spend on games), rather than just counting hardware numbers.
You’re so close to the answer. Now, why are PC gamers the ones still on 1080 and 1440 when everyone else has moved on?
Have I said anything in favor of crippling lower end cards or that these high prices of the high end cards are good? My only argument was that 4K displays in the PC space being the standard was simply delusional because the stats say something wholly different.
Well, people aren’t sticking 4090s in their Samsung smart TVs, so idk that matters.
I think it’s just an upselling strategy, although I agree I don’t think it makes much sense. Budget gamers really should look to AMD these days, but unfortunately Nvidia’s brand power is ridiculous.
An the issue for PC gamers is that Nvidia has spent the last few years convincing devs to shovel DLSS into everything, rather than a generic upscaling solution that other vendors could just drop their own algorithms into, meaning there’s a ton of games that won’t upscale nicely on anything else.
Before you claim 4k is the standard, you might wanna take a peak at the Steam hardware survey.
I don’t know anyone I game with that uses a 4k monitor. 1440p at your monitors max refresh rate is the favorite.
Sorry, crypto is back in season.
I swapped to AMD this generation and it’s still expensive.
A well researched pre-owned is the way to go. I bought a 6900xt a couple years ago for a deal.
I used to buy broken video cards on ebay for ~$25-50. The ones that run, but shut off have clogged heat sinks. No tools or parts required. Just blow out the dust. Obviously more risky, but sometimes you can hit gold.
If you can buy a ten and one works, you’ve saved money. Two work and you’re making money. The only question is whether the tenth card really will work or not.
And are you really interested in selling the extras?
Graphics cards are so bulky nowadays it’s often hard to even fit two on one mobo, as much as I’d love to see 10 GPUs all linked up.
Lol. I guess you’d need to go to a mining crypto den then, I hear they pull that sort of nonsense. ;)
But seriously though, I’m not interested in listing, shipping, and dealing w/ customer feedback just to save a few bucks on a GPU, because that sounds like a job.
For the price of the bundle? Sure.
Really? I’m far too lazy to list things like that. If I was, I’d be buying a lot more than 10 and make a little business out of it.
I used to get EVGA bstock which was reasonable but they got out of the business 😞
nope, if normal gamers are already willing to pay that price, no reason for nvidia to reduce them.
There’s more 4090 on steam than any AMD dedicated GPU, there’s no competition
AMD will go back to the same strategy they had with the RX 580. They don’t plan to release high end cards next generation. It seems they just want to pump out a higher volume of mid-tier (which is vague and subjective) while fixing hardware bugs plaguing the previous generation.
Hopefully, this means we can game on a budget while AMD is focusing primarily on marketshare.
Oh no!
Anyway…
I’ve been hearing about the imminent crash for the last two years. New money keeps getting injected into the system. The bubble can’t deflate while both the public and private sector have an unlimited lung capacity to keep puffing into it. FFS, bitcoin is on a tear right now, just because Trump won the election.
This bullshit isn’t going away. Its only going to get forced down our throats harder and harder, until we swallow or choke on it.
With the right level of Government support, bubbles can seemingly go on for literal decades. Case in point, Australian housing since the late 90s has been on an uninterrupted tear (yes, even in ‘08 and ‘20).
But eventually, bubbles either deflate or pop, because eventually governments and investors will get tired of propping it up. It might take decades, but I think it’s inevitable.
“The economics are likely to be grim,” Marcus wrote on his Substack. “Sky high valuation of companies like OpenAI and Microsoft are largely based on the notion that LLMs will, with continued scaling, become artificial general intelligence.”
“As I have always warned,” he added, “that’s just a fantasy.”
Even Zuckerberg admits that trying to scale LLMs larger doesn’t work because the energy and compute requirements go up exponentially. There must exist a different architecture that is more efficient, since the meat computers in our skulls are hella efficient in comparison.
Once we figure that architecture out though, it’s very likely we will be able to surpass biological efficiency like we have in many industries.
That’s a bad analogy. We weren’t able to surpass biological efficiency in industry sector because we figured out human anatomy and how to improve it. It’s simply alternative ways to produce force like electricity and motors which had absolutely no relation to how muscles works.
I imagine it would be the same for computers, simply another, better method to achieve something but it’s so uncertain that it’s barely worth discussing about.
Of course! It’s not like animals have jet engines!
Human brains are merely the proof that such energy efficiencies are possible for intelligence. It’s likely we can match or go far beyond that, probably not by emulating biology directly. (Though we certainly may use it as inspiration while we figure out the underlying principles.)
With current stat prediction models?
Microsoft shit is a mega corp… AI is based on their revenue lol
Well duhhhh.
Language models are insufficient.
They also need:
Someone in here has once linked me a scientific article about how today’s “AI” are basically one level below what they need to be anything like an AI. A bit like the difference between exponent and Ackermann function, but I really forgot what that was all about.
LLMs are AI. There’s a common misconception about what ‘AI’ actually means. Many people equate AI with the advanced, human-like intelligence depicted in sci-fi - like HAL 9000, JARVIS, Ava, Mother, Samantha, Skynet, and GERTY. These systems represent a type of AI called AGI (Artificial General Intelligence), designed to perform a wide range of tasks and demonstrate a form of general intelligence similar to humans.
However, AI itself doesn’t imply general intelligence. Even something as simple as a chess-playing robot qualifies as AI. Although it’s a narrow AI, excelling in just one task, it still fits within the AI category. So, AI is a very broad term that covers everything from highly specialized systems to the type of advanced, adaptable intelligence that we often imagine. Think of it like the term ‘plants,’ which includes everything from grass to towering redwoods - each different, but all fitting within the same category.
The stuff in computer games that makes NPCs move around the game world from point A to point B has been called AI for ages (and in this case specifically, is generally the A* pathing algorithm which isn’t even all that complex).
It’s only recently that marketing-types, salesmen and journalists with no actual technical expertise have started pushing AI as if the I in the acronym actually meant general intelligence rather than the “intelligence-alike” meaning that it has had for decades.
I know those terms. I wanted to edit it, but was too lazy. You still did understand what I meant, right?
We don’t call a shell script “AI” after all, and we do call those models that, while for your definition there shouldn’t be any difference.
deleted by creator
Huh?
The smartphone improvements hit a rubber wall a few years ago (disregarding folding screens, that compose a small market share, improvement rate slowed down drastically), and the industry is doing fine. It’s not growing like it use to, but that just means people are keeping their smartphones for longer periods of time, not that people stopped using them.
Even if AI were to completely freeze right now, people will continue using it.
Why are people reacting like AI is going to get dropped?
People are dumping billions of dollars into it, mostly power, but it cannot turn profit.
So the companies who, for example, revived a nuclear power facility in order to feed their machine with ever diminishing returns of quality output are going to shut everything down at massive losses and countless hours of human work and lifespan thrown down the drain.
This will have an economic impact quite large as many newly created jobs go up in smoke and businesses who structured around the assumption of continued availability of high end AI need to reorganize or go out of business.
Search up the Dot Com Bubble.
Because in some eyes, infinite rapid growth is the only measure of success.
People pay real money for smartphones.
People pay real Money for AIaaS as well…
It’s absurdly unprofitable. OpenAI has billions of dollars in debt. It absolutely burns through energy and requires a lot of expensive hardware. People aren’t willing to pay enough to make it break even, let alone profit
Eh, if the investment dollars start drying up, they’ll likely start optimizing what they have to get more value for fewer resources. There is value in AI, I just don’t think it’s as high as they claim.
Training new models is expensive. Running them can be fairly cheap. So no
Hope?
Because novelty is all it has. As soon as it stops improving in a way that makes people say “oh that’s neat”, it has to stand on the practical merits of its capabilities, which is, well, not much.
I’m so baffled by this take. “Create a terraform module that implements two S3 buckets with cross-region bidirectional replication. Include standard module files like linting rules and enable precommit.” Could I write that? Yes. But does this provide an outstanding stub to start from? Also yes.
And beyond programming, it is otherwise having positive impact on science and medicine too. I mean, anybody who doesn’t see any merit has their head in the sand. That of course must be balanced with not falling for the hype, but the merits are very real.
There’s a pretty big difference between chatGPT and the science/medicine AIs.
And keep in mind that for LLMs and other chatbots, it’s not that they aren’t useful at all but that they aren’t useful enough to justify their costs. Microsoft is struggling to get significant uptake for Copilot addons in Microsoft 365, and this is when AI companies are still in their “sell below cost and light VC money on fire to survive long enough to gain market share” phase. What happens when the VC money dries up and AI companies have to double their prices (or more) in order to make enough revenue to cover their costs?
Nothing to argue with there. I agree. Many companies will go out of business. Fortunately we’ll still have the llama3’s and mistral’s laying around that I can run locally. On the other hand cost justification is a difficult equation with many variables, so maybe it is or will be in some cases worth the cost. I’m just saying there is some merit.
I understand that it makes less sense to spend in model size if it isn’t giving back performance, but why would so much money be spent on larger LLMs then?
The merits are real. I do understand the deep mistrust people have for tech companies, but there’s far too much throwing out of the baby with the bath water.
As a solo developer, LLMs are a game-changer. They’ve allowed me to make amazing progress on some of my own projects that I’ve been stuck on for ages.
But it’s not just technical subjects that benefit from LLMs. ChatGPT has been a great travel guide for me. I uploaded a pic of some architecture in Berlin and it went into the history of it, I asked it about some damage to an old church in Spain - turned out to be from the Spanish civil war, where revolutionaries had been mowed down by Franco’s firing squads.
Just today, I was getting help from an LLM for an email to a Portuguese removals company. I sent my message in English with a Portuguese translation, but the guy just replied back with a single sentence in broken English:
“Yes a can , need tho mow m3 you need delivery after e gif the price”
The first bit is pretty obviously “Yes I can” but I couldn’t really be sure what he was trying to say with the rest of it. So I asked ChatGPT who responded:
It seems he’s saying he can handle the delivery but needs to know the total volume (in cubic meters) of your items before he can provide a price. Here’s how I’d interpret it:
“Yes, I can [do the delivery]. I need to know the [volume] in m³ for delivery, and then I’ll give you the price.”
Thanks to LLMs, I’m able to accomplish so many things that would have previously taken multiple internet searches and way more effort.
Okay now justify the cost it took to create the tool.
People differentiate AI (the technology) from AI (the product being peddled by big corporations) without making clear that nuance (Or they mean just LLMs, or they aren’t even aware the technology has a grassroots adoption outside of those big corporations). It will take time, and the bubble bursting might very well be a good thing for the technology into the future. If something is only know for it’s capitalistic exploits it’ll continue to be seen unfavorably even when it’s proven it’s value to those who care to look at it with an open mind. I read it mostly as those people rejoicing over those big corporations getting shafted for their greedy practices.
the bubble bursting might very well be a good thing for the technology into the future
I absolutely agree. It worked wonders for the Internet (dotcom boom in the 90s), and I imagine we’ll see the same w/ AI sometime in the next 10 years or so. I do believe we’re seeing a bubble here, and we’re also seeing a significant shift in how we interact w/ technology, but it’s neither as massive or as useless as proponents and opponents claim.
I’m excited for the future, but not as excited for the transition period.
I’m excited for the future, but not as excited for the transition period.
I have similar feelings.
I discovered LLMs before the hype ever began (used GPT-2 well before ChatGPT even existed) and the same with image generation models barely before the hype really took off. (I was an early closed beta tester of DALL-E)
And as my initial fascination grew, along with the interest of my peers, the hype began to take off, and suddenly, instead of being an interesting technology with some novel use cases, it became yet another technology for companies to show to investors (after slapping it in a product in a way no user would ever enjoy) to increase stock prices.
Just as you mentioned with the dotcom bubble, I think this will definitely do a lot of good. LLMs have been great for asking specialized questions about things where I need a better explanation, or rewording/reformatting my notes, but I’ve never once felt the need to have my email client generate every email for me, as Google seems to think I’d want.
If we can just get all the over-hyped corporate garbage out, and replace it with more common-sense development, maybe we’ll actually see it being used in a way that’s beneficial for us.
I initially started with natural language processing (small language models?) in school, which is a much simpler form of text generation that operates on words instead of whatever they call the symbols in modern LLMs. So when modern LLMs came out, I basically registered that as, “oh, better version of NLP,” with all its associated limitations and issues, and that seems to be what it is.
So yeah, I think it’s pretty neat, and I can certainly see some interesting use-cases, but it’s really not how I want to interface with computers. I like searching with keywords and I prefer the process of creation more than the product of creation, so image and text generation aren’t particularly interesting to me. I’ll certainly use them if I need to, but as a software engineer, I just find LLMs in all forms (so far) annoying to use. I don’t even like full text search in many cases and prefer regex searches, so I guess I’m old-school like that.
I’ll eventually give in and adopt it into my workflow and I’ll probably do so before the average person does, but what I see and what the media hypes it up to be really don’t match up. I’m planning to set up a llama model if only because I have the spare hardware for it and it’s an interesting novelty.
The hype should go the other way. Instead of bigger and bigger models that do more and more - have smaller models that are just as effective. Get them onto personal computers; get them onto phones; get them onto Arduino minis that cost $20 - and then have those models be as good as the big LLMs and Image gen programs.
Other than with language models, this has already happened: Take a look at apps such as Merlin Bird ID (identifies birds fairly well by sound and somewhat okay visually), WhoBird (identifies birds by sound, ) Seek (visually identifies plants, fungi, insects, and animals). All of them work offline. IMO these are much better uses of ML than spammer-friendly text generation.
those are all classification problems, which is a fundamentally different kind of problem with less open-ended solutions, so it’s not surprising that they are easier to train and deploy.
Platnet and iNaturalist are pretty good for plant identification as well, I use them all the time to find out what’s volunteering in my garden. Just looked them up and it turns out iNaturalist is by Seek.
This has already started to happen. The new llama3.2 model is only 3.7GB and it WAAAAY faster than anything else. It can thow a wall of text at you in just a couple of seconds. You’re still not running it on $20 hardware, but you no longer need a 3090 to have something useful.
Well, you see, that’s the really hard part of LLMs. Getting good results is a direct function of the size of the model. The bigger the model, the more effective it can be at its task. However, there’s something called compute efficient frontier (technical but neatly explained video about it). Basically you can’t make a model more effective at their computations beyond said linear boundary for any given size. The only way to make a model better, is to make it larger (what most mega corps have been doing) or radically change the algorithms and method underlying the model. But the latter has been proving to be extraordinarily hard. Mostly because to understand what is going on inside the model you need to think in rather abstract and esoteric mathematical principles that bend your mind backwards. You can compress an already trained model to run on smaller hardware. But to train them, you still need the humongously large datasets and power hungry processing. This is compounded by the fact that larger and larger models are ever more expensive while providing rapidly diminishing returns. Oh, and we are quickly running out of quality usable data, so shoveling more data after a certain point starts to actually provide worse results unless you dedicate thousands of hours of human labor producing, collecting and cleaning the new data. That’s all even before you have to address data poisoning, where previously LLM generated data is fed back to train a model but it is very hard to prevent it from devolving into incoherence after a couple of generations.
this is learning completely the wrong lesson. it has been well-known for a long time and very well demonstrated that smaller models trained on better-curated data can outperform larger ones trained using brute force “scaling”. this idea that “bigger is better” needs to die, quickly, or else we’re headed towards not only an AI winter but an even worse climate catastrophe as the energy requirements of AI inference on huge models obliterate progress on decarbonization overall.
That would be innovation, which I’m convinced no company can do anymore.
It feels like I learn that one of our modern innovations was already thought up and written down into a book in the 1950s, and just wasn’t possible at that time due to some limitation in memory, precision, or some other metric. All we did was do 5 decades of marginal improvement to get to it, while not innovating much at all.
Are you talking about something specific?
I think I’ve heard about enough of experts predicting the future lately.
Marcus is right, incremental improvements in AIs like ChatGPT will not lead to AGI and were never on that course to begin with. What LLMs do is fundamentally not “intelligence”, they just imitate human response based on existing human-generated content. This can produce usable results, but not because the LLM has any understanding of the question. Since the current AI surge is based almost entirely on LLMs, the delusion that the industry will soon achieve AGI is doomed to fall apart - but not until a lot of smart speculators have gotten in and out and made a pile of money.
Because nobody could have possibly saw that coming. /s





















