
- cross-posted to:
- [email protected]
- cross-posted to:
- [email protected]
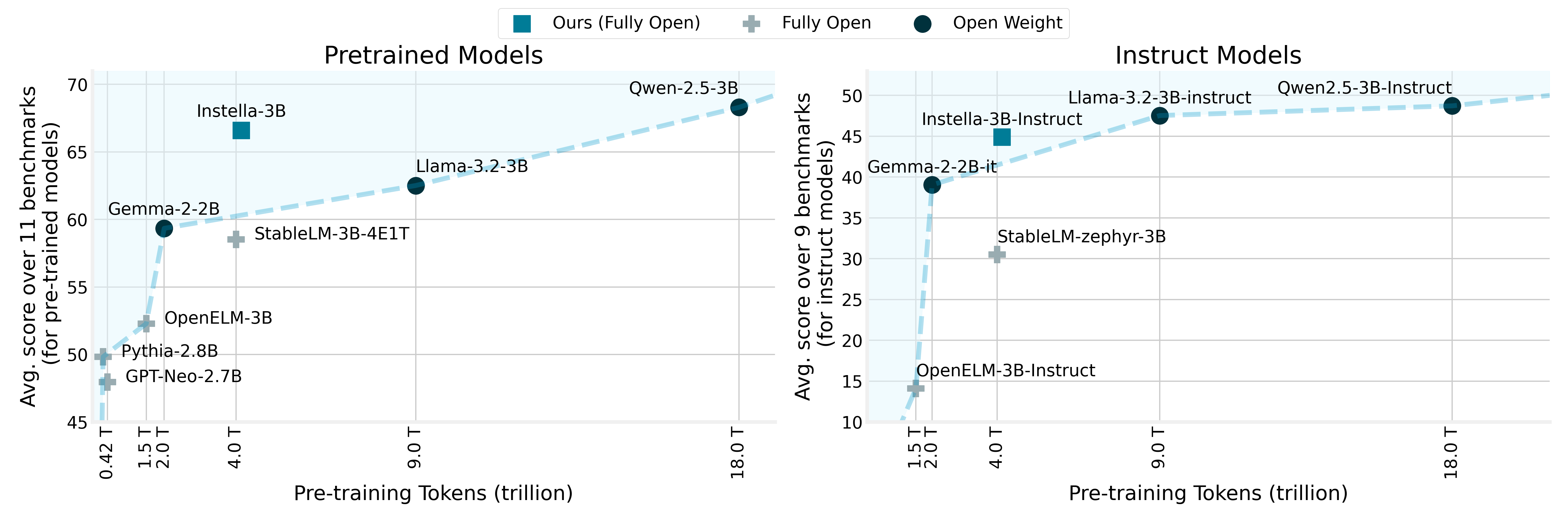
This is again a big win on the red team at least for me. They developed a “fully open” 3B parameters model family trained from scratch on AMD Instinct™ MI300X GPUs.
AMD is excited to announce Instella, a family of fully open state-of-the-art 3-billion-parameter language models (LMs) […]. Instella models outperform existing fully open models of similar sizes and achieve competitive performance compared to state-of-the-art open-weight models such as Llama-3.2-3B, Gemma-2-2B, and Qwen-2.5-3B […].
As shown in this image (https://rocm.blogs.amd.com/_images/scaling_perf_instruct.png) this model outperforms current other “fully open” models, coming next to open weight only models.
A step further, thank you AMD.
PS : not doing AMD propaganda but thanks them to help and contribute to the Open Source World.
You must log in or register to comment.
Properly open source.
The model, the weighting, the dataset, etc. every part of this seems to be open. One of the very few models that comply with the Open Software Initiative’s definition of open source AI.
Look at the picture in my post.
There was others open models but they were very below the “fake” open source models like Gemma or Llama, but Instella is almost to the same level, great improvement
3B
That’s one more than 2B so she must be really hot!
/nierjokes
AMD knew what they were doing.
That’s a real stretch. 3B is basically stating the size of the model, not the name of the model.
Are you calling her fat?
Can’t judge you for wanting to **** her or whatever, just don’t ask her for freebies. She won’t care if you are a human at that point.
Every AI model outperforms every other model in the same weight class when you cherry pick the metrics… Although it’s always good to have more to choose from
I’ve shared this AI because it’s one of the best fully open source AI
Nice and open source . Similar performance to Qwen 2.5.
(also … https://www.tomsguide.com/ai/i-tested-deepseek-vs-qwen-2-5-with-7-prompts-heres-the-winner ← tested DeepSeek vs Qwen 2.5 … )
→ Qwen 2.5 is better than DeepSeek.
So, looks good.Dont know if this test in a good representation of the two AI, but in this case it seems pretty promising, the only thing missing is a high parameters model
And we are still waiting on the day when these models can actually be run on AMD GPUs without jumping through hoops.
In other words, waiting for the day when antitrust law is properly applied against Nvidia’s monopolization of CUDA.
That is a improvement, if the model is properly trained with rocm it should be able to run on amd GPU easier
Help me understand how this is Open Source? Perhaps I’m missing something, but this is Source Available.
Instead of the traditional open models (like llama, qwen, gemma…) that are only open weight, this model says that it has :
Fully open-source release of model weights, training hyperparameters, datasets, and code
Making it different from other big tech “open” models. Tough it exists other “fully open” models like GPT neo, and more
The source code on these models is almost too boring to care about. Training data and weights is what really matters.
OpenCL not mentioned, and so raw hardware level code most likely. Maybe no one else cares, but higher level code means more portability.
What is the link with rocm?
AMD uses opencl as its high level API. Nvidia, Intel also supports it. Chinese cards might too. Very few LLMs use high level APIs such as CUDA or OpenCL
I know it’s not the point of the article but man that ai generated image looks bad. Like who approved that?
Oh yeah you’re right :-)
Nice. Where do I find the memory requirements? I have an older 6GB GPU so I’ve been able to play around with some models in the past.
No direct answer here, but my tests with models from HuggingFace measured about 1.25GB of VRAM per 1B parameters.
Your GPU should be fine if you want to play around.
LMstudio usually lists the memory recommendations for the model.
Following this page it should be enough based on the requirements of qwen2.5-3B https://qwen-ai.com/requirements/
I am looking forward to worryingly small models. There’s nothing magical about the b-for-billion barrier, and trained models can be pruned. Between that and the flexible nature of quantization… I want to see an 8K JPEG that speaks English.
Slap your dick on the table and announced CUDA support.
People have a right to software.
I think that we need to improve rocm as today nividia dont want do give their “secret sauce” to the public
Fuck Nvidia
Why open themselves up to a massive copyright violation lawsuit?
Copyright isn’t what protects that.
And the motivation is the shitload of money Nvidia stole from them by making computation proprietary.
edit: Whoops, server said it didn’t get that.
Copyright isn’t what protects that.
But it is. Look at Google v Oracle, which was an incredibly similar case that looked at whether Google using Oracle’s API documentation fell under copyright’s notion of “fair use.” If AMD tries to copy CUDA, they’ll likely run into a similar court case, especially if AMD uses anything past surface-level documentation. Whether they win or lose is sort of irrelevant since Nvidia will most likely be granted a stay, which will impact AMD.
And this doesn’t even get into the issues around AMD always having to play catch-up, since Nvidia is in full control of the “standard” and can make changes at any time.
The proper approach is for this type of thing to be an open standard so everyone is competing on a fair playing field w/o any concerns about copyright violations. ROCm is open source, so much closer to that ideal. Intel’s OneAPI is also open source, but unfortunately AMD and Intel aren’t really collaborating here, and they kind of need to in order to cut into Nvidia’s marketshare.
The case that didn’t reach a decision on whether APIs fall under copyright, because re-implementing an API wouldn’t count as infringement anyway?
And this doesn’t even get into the issues around AMD always having to play catch-up, since Nvidia is in full control of the “standard” and can make changes at any time.
Underlining and bolding how Nvidia has a monopoly and engages in anti-competitive practices.
The case that didn’t reach a decision on whether APIs fall under copyright
It sort of did:
The Court issued its decision on April 5, 2021. In a 6–2 majority, the Court ruled that Google’s use of the Java APIs was within the bounds of fair use, reversing the Federal Circuit Appeals Court ruling and remanding the case for further hearing. Justice Stephen Breyer wrote the majority opinion. Breyer’s opinion began with the assumption that the APIs may be copyrightable, and thus proceeded with a review of the four factors that contributed to fair use:
The Supreme Court decision explicitly cites the Fair Use doctrine of copyright law in its decision about Google’s use.
My concern is that CUDA is different enough from the Google v Oracle case that the precedent isn’t as clear-cut.
Underlining and bolding how Nvidia has a monopoly and engages in anti-competitive practices.
That’s not anti-competitive, at least not under what I understand from anti-trust law. It would be anti-competitive if Nvidia, for example, competitor drivers from running on the same machine or something, or having something in the contract that forbids using other GPU vendors products in a datacenter.
Nvidia has to go out of their way to prevent competition to trigger anti-trust, just having a popular product and not warning competitors when you make a change to a format you 100% control doesn’t trigger that. Maybe there’s an argument that they should once their marketshare goes above a certain amount, but AFAIK that’s not a violation of anti-trust as it stands.
Does may mean are?
Fair use makes the question irrelevant. Oracle failed twice: if they’d proved beyond question that their API is copyrighted, Google was still free to replicate it. So copyrightability wasn’t worth considering.
Nvidia has to go out of their way to prevent competition to trigger anti-trust
‘Actively preventing compatibility isn’t preventing competition’ is quite a fucking take.
Their market share of the AI bubble is all of it. Because as people in this thread will tell you: AMD cards are actively prevented from competing with Nvidia cards, specifically and entirely because of CUDA.
So copyrightability wasn’t worth considering.
Yes, because the result would be the same whether it is or isn’t. That means the precedent is murky, which leaves future cases open to consideration.
‘Actively preventing compatibility isn’t preventing competition’ is quite a fucking take.
How so? There’s no assumption of compatibility between devices. If Microsoft changes some APIs on Windows, WINE developers on Linux have no room to claim anti-competitive behavior, they just need to adapt. Assuming that APIs are frozen just because some competitor is basing a product them is bonkers.
The Windows v US anti-trust issue was because was intentionally making performance worse for competition while opening up APIs for only internal use. That’s not what’s happening w/ Nvidia at all, they’re just pushing an API, much like Windows pushes DirectX, and application developers are free to use it, or not. If AMD wants to copy that API, they would have to adapt to any compatibility issues, much like WINE does with Windows APIs.
AMD cards are actively prevented from competing with Nvidia cards, specifically and entirely because of CUDA.
Other vendors not building compatibility for AMD’s products isn’t “preventing competition.” AMD is free to create a better product, but Nvidia is currently wiping the floor with them hardware-wise, and they’re trying to lock people in on the software side. AMD’s approach should be to:
- make better hardware to target the AI market; (benchmarks show Nvidia is dominating)
- proactively build in compatibility to the various projects that operate in that space
- market their products at an attractive price point to encourage customers to give them a shot
They’re finally doing #3 for the consumer market with the 9070/9070XT cards. I haven’t been tracking their enterprise offerings, so I don’t know if they’re trying to make inroads there, or just want to expand in consumer first and deal w/ AI later.
It’s about AI.
I don’t know why open sourcing malicious software is worthy of praise but okay.
I’ll bite, what is malicious about this?
What’s malicious about AI and LLMs? Have you been living under a rock?
At best it is useless, and at worst it is detrimental to society.
I disagree, LLMs have been very helpful for me and I do not see how an open source AI model trained with open source datasets is detrimental to society.
I don’t know what to say other than pull your head outta the sand.
No you.
Explain your exact reasons for thinking it’s malicious. There’s a lot of FUD surrounding “AI,” a lot of which come from unrealistic marketing BS and poor choices by C-suite types that have nothing to do with the technology itself. If you can describe your concerns, maybe I or others can help clarify things.
These models are trained on human creations with the express intent to drive out those same human creators. There is no social safety net available so those creators can maintain a reasonable living standard without selling their art. It won’t even work–the models aren’t good enough to replace these jobs, but they’re good enough to fool the C-suite into thinking they can–but they’ll do lots of damage in the attempt.
The issues are primarily social, not technical. In a society that judges itself on how well it takes care of the needs of everyone, I would have far less of an issue with it.
The issues are primarily social, not technical.
Right, and having a FOSS alternative is certainly a good thing.
I think it’s important to separate opposition to AI policy from a specific implementation. If your concerns are related to the social impact of a given technology, that is where the opposition should go, not toward the technology itself.
That said, this is largely similar to opposition to other types of technological change. Every time a significant change in technology comes about, there is a significant impact to jobs. The printing press destroyed the livelihood of scribes, but it made books dramatically cheaper, which created new jobs for typesetters, booksellers, etc. The automobile dramatically cut back jobs like farriers, stable hands, etc, but created new jobs for drivers, mechanics, etc. I’m sure each of those large shifts in technology also had an overreaction by business owners as they adjusted to the new normal. It certainly sucks for those impacted, but it tends to benefit those who can quickly adapt and make use of the new technology.
So I totally understand the hesitation around AI, especially given the overreaction by C-suites in gutting their workforce based on the promises made by AI marketing teams. However, that has nothing to do with the technology, but the social issues around the technology. Instead of hating AI in general, redirect that anger onto the actual problems:
- poor social safety net
- expensive education
- lack of consequences for false marketing
- lack of consequences for C-suite mistakes
Hating on a FOSS model just because it’s related to an industry that is seeing abuse is the wrong approach.






{kind=link}