

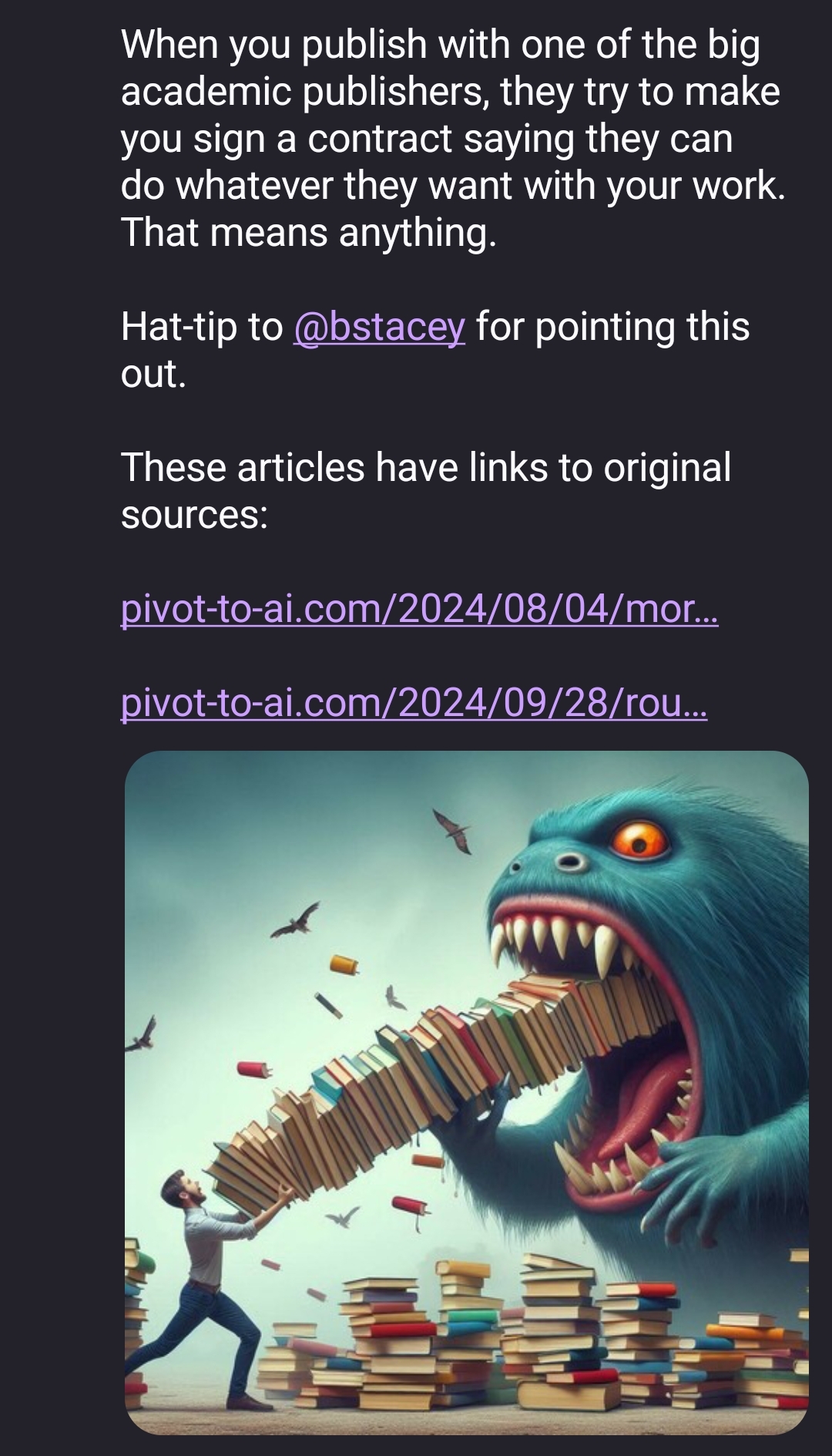
Taylor & Francis and Wiley sold out their researchers in bulk, this should be a crime.
Researchers need to be able to consent or refuse to consent and science need to be respected more than that.
You must log in or register to comment.
Oh look! Socialism for the rich!
🧑🚀🔫🧑🚀
See - this is why I don’t give a shit about copyright.
It doesn’t protect creators - it just enriches rent-seeking corporate fuckwads.
Daily reminder that copyright isn’t the only conceivable weapon we can wield against AI.
Anticompetitive business practices, labor law, privacy, likeness rights. There are plenty of angles to attack from.
Most importantly, we need strong unions. However we model AI regulation, we will still want some ability to grant training rights. But it can’t be a boilerplate part of an employment/contracting agreement. That’s the kind of thing unions are made to handle.
Look, I’m not against AI and automation in general. I’m not against losing my job either. We should use this as tools to overcome scarcity, use it for the better future of all of humanity. I don’t mind losing my job if I could use my time to do things I love. But that won’t happen as long as greedy ass companies use it against us.
We conquered our resource scarcity problem years ago. Artificial scarcity still exists in society because we haven’t conquered our greed problem.
Both of you argue from the flawed assumption that AI actually has the potential that marketing people trying to bullshit you say it has. It doesn’t.
AI has its usage. Not the ones people cream their pants about, but to say it’s useless is just wrong. But people tend to misunderstand what AI, ML, and whatever else is. Just like everyone was celebrating the cloud without knowing what the cloud was ten, twenty years ago.
It has its uses but none of them include anything even close to replacing entire jobs or even significant portions of jobs.
I disagree, but I might have different experiences.
It doesn’t matter what it’s good for. What matters is what the MBA parasites think it’s good for.
They will impulsively replace jobs, and then when it fails, try to rehire at lower wages.
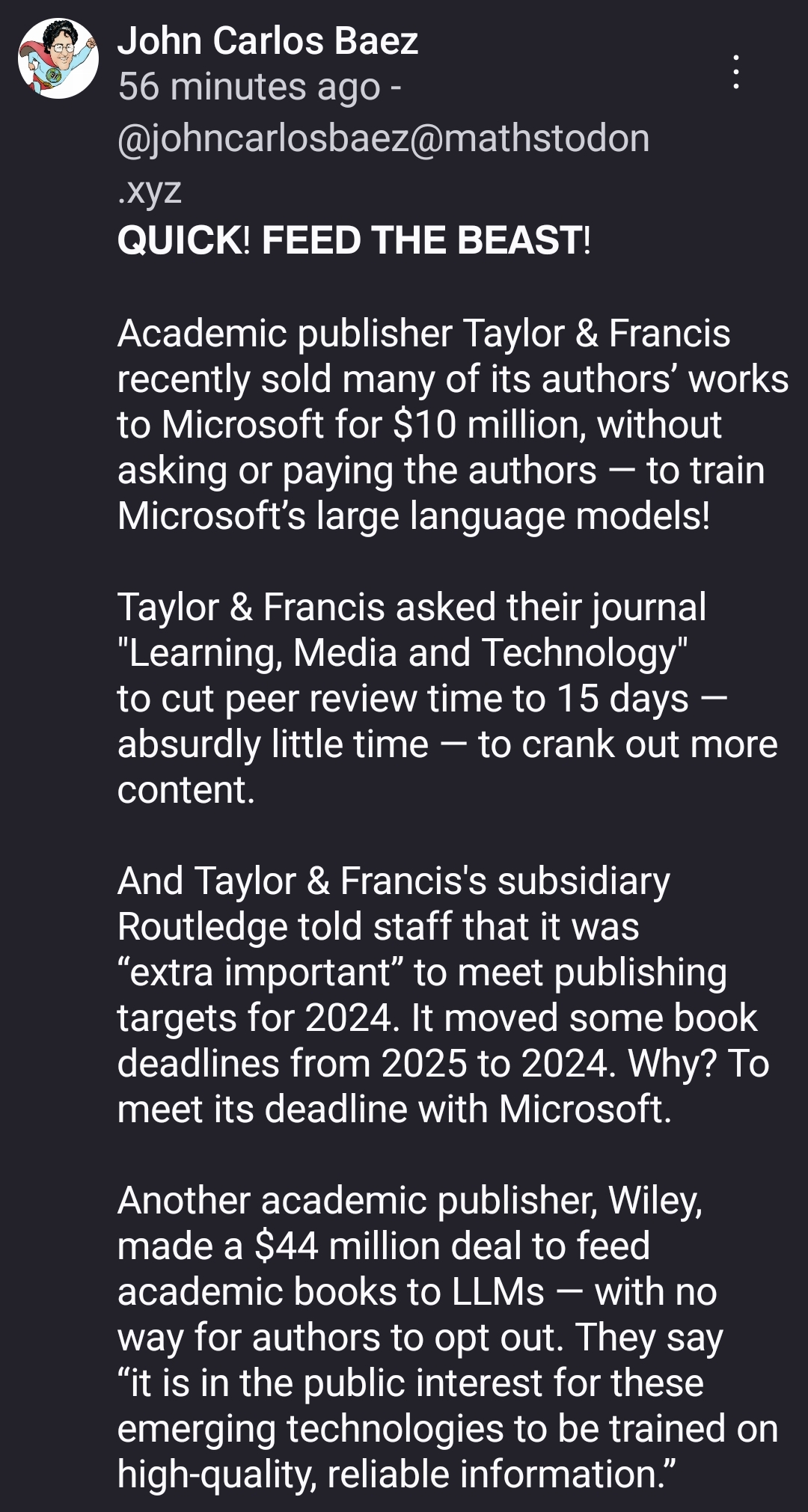
“it is in the public interest for these emerging technologies to be trained on high-quality, reliable information.”
Oh, well if you say so. Oh wait, no one has a say anyway because corporations ru(i)n everything.
“We need to train LLMs with your data in order to make you obsolete.”
If that’s what it takes to get rid of CEOs then I’m on board.
Seriously though, that’s the best application of AI. CEO is a simple logic based position, or so they tell us, that happens to consume more financial resources than many dozen lower level employees. If anyone is on the chopping block it should be them, in both senses of the phrase.
For CEOs it might even bring down the percentage of nonsense they say even with the high rates of nonsense AI produces.
It’s nice to see them lowering the bar for “high-quality” at the same time. Really makes it seem like they mean it. /s
“it’s in the public interest” so all these articles will be freely available to the public. Right?.. Riiight?!
“How is nobody talking about this?”
The average person has the science literacy at or below a fifth grader, and places academic study precedence below that of a story about a wish granting sky fairy who made earth in his basement as a hobby with zero lighting (obviously, as light hadn’t been invented at that point).
A musician friend of mine, when asked “Why are there no Mozarts or Beethovens any more?” replies “We went through your schools.”
Is this an anti-education comment or…?
Quite the contrary! The idea is that today’s curricula and methods of instruction have changed a lot over two centuries. Here in the US, it is not uncommon for secondary arts teachers and programs to be dropped whenever schools are feeling a budget crunch. Now we see similar things going on in major universities. Often ones with more administrators than professors.
In the high school I attended, and later in one that I taught in, the separate building for the sports program was as large as the rest of the school. I thought those were fairly clear statements of what the district’s priorities were. ‘Education’ is a very broad word that can mean many things in many places.
Ah yeah, fuck administration sometimes. Bunch of corporate shills operating the Universities these days, really makes me wonder if we’ll have a more open access method to accredited education very soon, if only because of the enshitification of top schools.
I ran into a very old saying yesterday: A fish rots from the head down.
Careful, you might cut yourself with that edge
I will not be called unrealistic by a cancelled nickelodeon puppet from the 90s.
deleted by creator
It’s for reasons like these that I think its foolhardy to be advocating for a strengthening of copyrights when it comes to AI.
The windfall will not be shared, the data is already out of the hands of the individuals and any “pro-artist” law will only help kill the competition for companies like Google, Sony Music, Disney and Microsoft.
These companies will happily pay huge sums to lock anyone out of the scene. They are already splitting it between each other, they are anticipating a green light for regulatory capture.
Copyright is not supposed to be protecting individuals work from corporations, but the otherway around
I think this happens because the publisher owns the content and owes royalties to authors under certain conditions (which may or may not be met in this situation). The reason I think this is I had a PhD buddy who published a book (nonfiction history) and we all got a hardy chuckle at the part of the contract that said the publisher got the theme park rights. But what if there were other provisions in the contract that would allow for this situation without compensating the authors? Anywho, this is a good reminder to read the fine print on anything you sign.
I’d guess books are different, but researchers don’t get paid anything for publishing in academic journals
Oh yeah, good point.
Guess it’s time to poison the data
A couple dozen zero-width unicode characters between every letter, white text on white background filled with nonsense, any other ideas?
Hilariously the data is poisoning itself, because as the criteria for decent review are dwindling, more non - reproducible crap science is published. Or its straight up fake. Journals don’t care, correcting the scientific record always takes months or years. Fuck the publishers.
How does cutting peer review time help get more content? The throughput will still be the same regardless of if it takes 15 days or a year to complete a peer review
Isn’t that because the peers also write stuff? So it’s not just a fixed delay on one-by-one papers, but a delay that goes between peers’ periods of working on papers too.
Reminds me of the song “Feed the Machine” by Poor Man’s Poison:
deleted by creator
The shitty chat bots do need high quality data. This is much better than scraping off reddit, since a glorified auto-complete cannot know that eating rocks is bad for you. You can’t retroactively complain after having signed away your rights to something. But you can change things moving forward. If you are incorruptible and don’t care about money, start an organization with those values and convince the researchers to join you. Good luck (seriously, I hope you succeed).
Meh who cares. AI is gonna be more correct now. It costs nothing to use (if you run your own locally), and nothing to not use. Just don’t use it if you hate it so much and for the love of god touch grass and get off twitter, that place is hell on earth.
Despite the downvotes I’m interested why you think this way…
The common Lemmy view is that morally, papers are meant to contribute to the sum of human knowledge as a whole, and therefore (1) shouldn’t be paywalled in a way unfair to authors and reviewers – they pay the journals, not the other way around – and (2) closed-source artificially intelligent word guessers make money off of content that isn’t their own, in ways that said content-makers have little agency or say, without contributing back to the sum of human knowledge by being open-source or transparent (Lemmy has a distaste for the cloisters of venture capital and multibillion-parameter server farms).
So it’s not about using AI or not but about the lack of self-determination and transparency, e.g. an artist getting their style copied because they paid an art gallery to display it, and the art gallery traded rights to image generation companies without the artists’ say (although it can be argued that the artists signed the ToS, though there aren’t any viable alternatives to avoiding the signing).
I’m happy to listen if you differ!
I won’t say that AI is the greatest thing since sliced bread but it is here and it’s not going back in the bottle. I’m glad to see that we’re at least trying to give it accurate information, instead of “look at all this user data we got from Reddit, let’s have searches go through this stuff first!” Then some kid asks if it’s safe to go running with scissors and the LLM says “yes! It’s perfectly fine to run with sharp objects!”
The tech kinda really sucks full stop, but it’ll be marginally better if it’s information is at least accurate.
Hmm, that makes sense. The toothpaste can’t go back into the tube, so they’re going a bit deeper to get a bit higher.
That does shift my opinion a bit – something bad is at least being made better – although the “let’s use more content-that-wants-to-be-open in our closed-content” is still a consternation.
Not wrong there, it’s one of the things that makes me critical of genai
This could be true if they were to give more weight to academic sources, but I fear it will probably treat them like any other source, so a published paper and some moron on Reddit will still get the same say on wether the Earth is round.
I promise you, they absolutely will treat it as equally valid input data.
(1) shouldn’t be paywalled in a way unfair to authors and reviewers – they pay the journals, not the other way around –
Yes of course. It’s not at all relevant?
(2) closed-source artificially intelligent word guessers make money off of content that isn’t their own, in ways that said content-makers have little agency or say, without contributing back to the sum of human knowledge by being open-source or transparent
Yeah that’s why I’m pro-AI, not only is it very literally transparent and most models open-weight, and most libraries open-source, but it’s making knowledge massively more accessible.
I used to teach people to Google, but there is no point, now it’s like a dark pattern, with very little reward for a lot of effort, because everything, especially YouTube is now a grift. Now I teach them how to proompt without also rotting their brain by outsourcing actual intellectual work rather than pure fact-finding.
Yes it is a bit shit at being correct, it hallucinates, but frankly to paraphrase Turing, infallibility is not a quality of intelligence.
And more practically if Joe Schmoe can’t think critically and has to trust unquestionably then I’d rather he trust gippity than the average Facebook schizo.
With that in mind I see no reason not to feed it products of the scientific method, the most rigorous and highest solution to the problems of epistemology we’ve come up with thus far.
but about the lack of self-determination and transparency
Because frankly if you actually read the terms and conditions when you signed up to Facebook and your weird computer friends were all scoffing at the privacy invasion and if you listened to the experts then you and these artists would not feel like you were being treated unfairly, because not only did you allow it to happen, you all encouraged it. Now that it might actually be used for good, you are upset. It’s disheartening. I’m sorry, most of you signed it all away by 2006. Data is forever.
an artist getting their style copied
So if I go to an art gallery for inspiration I must declare this in a contract too? This is absurd. But to be fair I’m not surprised. Intellectual property is altogether an absurd notion in the digital age, and insanity like “copyrighting styles” is just the sharpest most obvious edge of it.
I think also the fearmongering about artists is overplayed by people who are not artists. For all it’s worth I’ve never heard this vehement anti-AI take outside of like Twitter and Reddit comment sections and I know plenty of artists, and those I do actually follow e.g. on YT are actually either skeptical but positive or using it already as part of their workflow even if they do have criticisms of the industry.
(Which I do of course too, in the sense that there should not be any industry for as long as the oppression of capital reigns supreme.)
Actually the only prolific individual of any kind that has voiced this opinion that I’m aware of is Hbomberguy who is self-admittedly a bit of an idiot, and it is obviously a tacked on claim with no real nuance or addressing of opposing views or sources for even the basic claims (which are completely wrong) at the end of a video about a completely different topic that makes the video seem more relevant and topical than it is.
Thanks for the detailed reply! :P
I’d like to converse with every part of what you pointed out – real discussions are always exciting!
…they pay the journals, not the other way around…
Yes of course. It’s not at all relevant?
It’s arguably relevant. Researchers pay journals to display their years of work, then these journals resell those years of work to AI companies who send indirect pressure to researchers for more work. It’s a form of labor where the pay direction is reversed. Yes, researchers are aware that their papers can be used for profit (like medical tech) but they didn’t conceive that it would be sold en masse to ethically dubious, historically copyright-violating, pollution-heavy server farms. Now, I see that you don’t agree with this, since you say:
…not only is it very literally transparent and most models open-weight, and most libraries open-source, but it’s making knowledge massively more accessible.
but I can’t help but feel obliged to share the following evidence.
- Though a Stanford report notes that most new models are open source (Lynch, 2024), the models with the most market-share (see this Forbes list) are not open-source. Of those fifty, only Cleanlab, Cohere, Hugging Face (duh), LangChain (among other Python stuff like scikit-learn or tensorflow), Weaviate, TogetherAI and notably Mistral are open source. Among the giants, OpenAI’s GPT-4 et al., Claude, and Gemini are closed-source, though Meta’s LLaMa is open-source.
- Transparency is… I’ll cede that it is improving! But it’s also lacking. According to the Stanford 2024 Foundation Model Transparency Index, which uses 100 indicators such as data filtration transparency, copyright transparency, and pollution transparency (Bommasani et al., 2024, p. 27 fig. 8), developers were opaque, including open-source developers. The pertinent summary notes that the mean FMTI company score improved from 37 to 58 over the last year, but information about copyright data, licenses, and guardrails have remained opaque.
I see you also argue that:
With [the decline of effort in average people’s fact-finding] in mind I see no reason not to feed [AI] products of the scientific method, [which is] the most rigorous and highest solution to the problems of epistemology we’ve come up with thus far.
And… I partly agree with you on this. As another commenter said, “[AI] is not going back in the bottle”, so might as well make it not totally hallucinatory. Of course, this should be done in an ethical way, one that respects the rights to the data of all involved.
But about your next point regarding data usage:
…if you actually read the terms and conditions when you signed up to Facebook… and if you listened to the experts then you and these artists would not feel like you were being treated unfairly, because not only did you allow it to happen, you all encouraged it. Now that it might actually be used for good, you are upset. It’s disheartening. I’m sorry, most of you signed it all away by 2006. Data is forever.
That’s a mischaracterization of a lot of views. Yes, a lot of people willfully ignored surveillance capitalism, but we never encouraged it, nor did we ever change our stance from affirmatory to negative because the data we intentionally or inadvertently produced began to be “used for good”. One of the earliest surveillance capitalism investigators, Harvard Business School professor Shoshana Zuboff, confirms that we were just scared and uneducated about these things outside of our control.
“Every single piece of research, going all the way back to the early 2000s, shows that whenever you expose people to what’s really going on behind the scenes with surveillance capitalism, they don’t want anything to do [with] it. The only reason we keep engaging with it is because we feel like we have no choice. …[it] is a colossal market failure. Because it is not giving people what people want. …everything that’s inside that choice [i.e. the choice of picking between convenience and privacy] has been designed to keep us in ignorance.” (Kulwin, 2019)
This kind of thing – corporate giants giving up thousands of papers to AI – is another instance of people being scared. But it’s not fearmongering. Fearmongering implies that we’re making up fright where it doesn’t really exist; however, there is indeed an awful, fear-inducing precedent set by this action. Researchers now have to live with the idea that corporations, these vast economic superpowers, can suddenly and easily pivot into using all of their content to fuel AI and make millions. This is the same content they spent years on, that they intended for open use in objectively humanity-supporting manners by peers, the same content they had few alternative options for storage/publishing/hosting other than said publishers. Yes, they signed the ToS and now they’re eating it. We’re evolving towards the future at breakneck pace – what’s next? they worry, what’s next?
(Comment 1/2)
Speaking of fearmongering, you note that:
an artist getting their style copied
So if I go to an art gallery for inspiration I must declare this in a contract too? This is absurd. But to be fair I’m not surprised. Intellectual property is altogether an absurd notion in the digital age, and insanity like “copyrighting styles” is just the sharpest most obvious edge of it.
I think also the fearmongering about artists is overplayed by people who are not artists.
Ignoring the false equivalency between getting inspiration at an art gallery and feeding millions of artworks into a non-human AI for automated, high-speed, dubious-legality replication and derivation, copyright is how creative workers retain their careers and find incentivization. Your Twitter experiences are anecdotal; in more generalized reality:
- Chinese illustrator jobs purportedly dropped by 70% in part due to image generators
- Lesser-known artists are being hindered from making themselves known as visual art venues close themselves to known artists in order to reduce AI-generated issues – the opposite of democratizing art
- Artists have reported using image generators to avoid losing their jobs
- Artists’ works, such as those by Hollie Mengert and Karen Hallion among others, have been used without their compensation, attribution, nor consent in training data – said style mimicries have been described as “invasive” (someone can steal your mode of self-expression) and reputationally damaging – even if the style mimicries are solely “surface-level”
The above four points were taken from the Proceedings of the 2023 AIII/ACM Conference on AI, Ethics, and Society (Jiang et al., 2023, section 4.1 and 4.2).
Help me understand your viewpoint. Is copyright nonsensical? Are we hypocrites for worrying about the ways our hosts are using our produced goods? There is a lot of liability and a lot of worry here, but I’m having trouble reconciling: you seem to be implying that this liability and worry are unfounded, but evidence seems to point elsewhere.
Thanks for talking with me! ^ᴗ^
(Comment 2/2)








{kind=link}